Week 1 — Hyperparameter tuning: searching for the best architecture
Overview
This course is focuses on tools and techniques to effectively manage modeling resources and best serve batch and real-time inference requests.
- Effective search strategies for the best model that will scale for various serving needs
- Constraining model complexity and hardware requirements
- Optimize and manage compute storage and IO needs
- We'll be going through TensorFlow Model Analysis (TFMA)
Neural Architecture Search
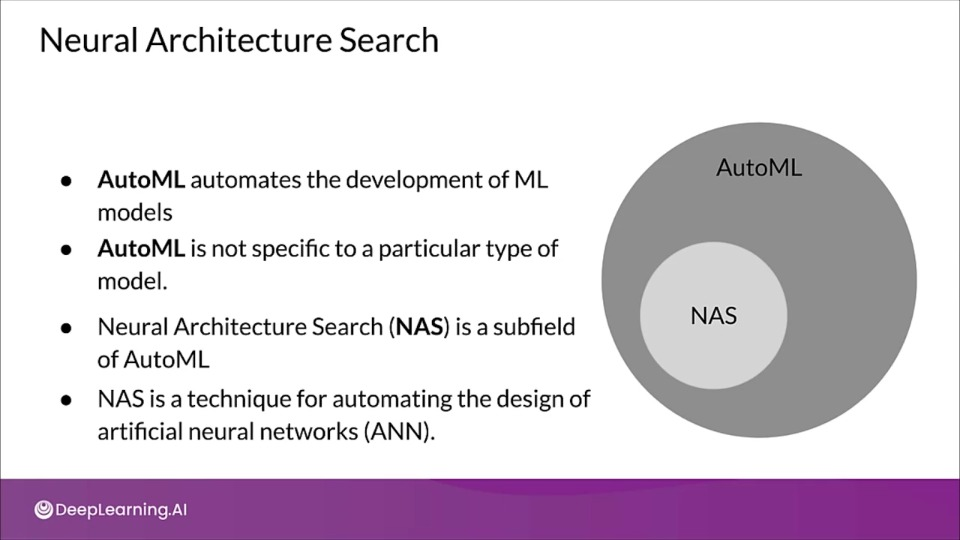
- Neural architecture search (NAS) is a technique for automating the design of artificial neural networks
- It helps finding the optimal architecture
- This is a search over a huge space
- AutoML is an algorithm to automate this search
Types of parameters in ML models
- Trainable parameters
- Learned by the algorithm during training
- e.g., weights of a neural network
-
Hyperparameters
- Set before launching the learning process
- not updated in each training step
Hyperparameters are of two types:
- Model hyperparameters which influence model selection such as the number and width of hidden layers
- Algorithm hyperparameters which influence the speed and quality of the learning algorithm such as the learning rate for Stochastic Gradient Descent (SGD) and the number of nearest neighbors for a k Nearest Neighbors (KNN) classifier.
- e.g., learning rate or the number of units in a dense layer
Manual hyperparameter tuning is not scalable
The process of finding the optimal set of hyperparameters is called hyperparameter tuning or hypertuning.
- Hyperparameters can be numerous even for small models
- e.g., shallow DNN
- Architecture choices
- activation functions
- Weight initialization strategy
- Optimization hyperparameters such as learning rate, stop condition
- Tuning them manually can be a real brain teaser
- helps boost model performance.
Automating hyperparameter tuning with Keras Tuner
- Automation is key.
- Keras Tunes:
- Hyperparameter tuning with TensorFlow 2.0
- Many methods available>
Keras Autotuner Demo
- Do the model need more or less hidden units to perform well?
- How does model size affect the convergence spped?
- Is there any trade off between convergence speed, model size and accuracy?
- Search automation is the natural path to take
- keras tuner built in search functionality will help!
- Keras Tuner has four tuners available with built-in strategies:
RandomSearchHyperbandBayesianOptimizationSklearn
import keras_tuner as kt
def model_builder(hp):
'''
Builds the model and sets up the hyperparameters to tune.
Args:
hp - Keras tuner object
Returns:
model with hyperparameters to tune
'''
# The model you set up for hypertuning is called a hypermodel.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
hp_units = hp.Int('units', min_value=16, max_value=512, step=16)
model.add(keras.layers.Dense(units=hp_units, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(keras.layer.Dense(10))
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
return model
# Keras tuner support multiple strategies, one we're using is Hyperband strategy
# Keras Tuner has four tuners available with built-in strategies - RandomSearch, Hyperband, BayesianOptimization, and Sklearn
tuner = kt.Hyperband(
model_builder,
objective='val_accuracy',
max_epochs=10,
factor=3,
directory='my_dir',
project_name='intro_to_kt')
# callback configuration
stop_early = tf.keras.callbacks.EarlyStopping(
monior='val_loss', patience=5)
tuner.search(
X_train, y_train,
epochs=50,
validation_split=0.2,
callbacks=[stop_early])
Search Output
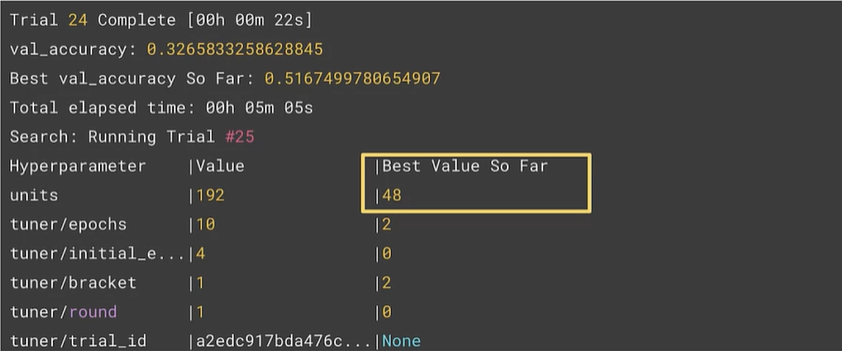
Then, we can set the hidden units to be 48
best_hps=tuner.get_best_hyperparameters()[0]
h_model = tuner.hypermodel.build(best_hps)
h_model.fit(X_train, y_train, epochs=NUM_EPOCHS, validation_split=0.2)
AutoML — Intro to AutoML (Automated Machine Learning)
It is aimed at developers with very little experience in ML to make use of ML model and techniques by trying to automate entire workflow end-to-end.
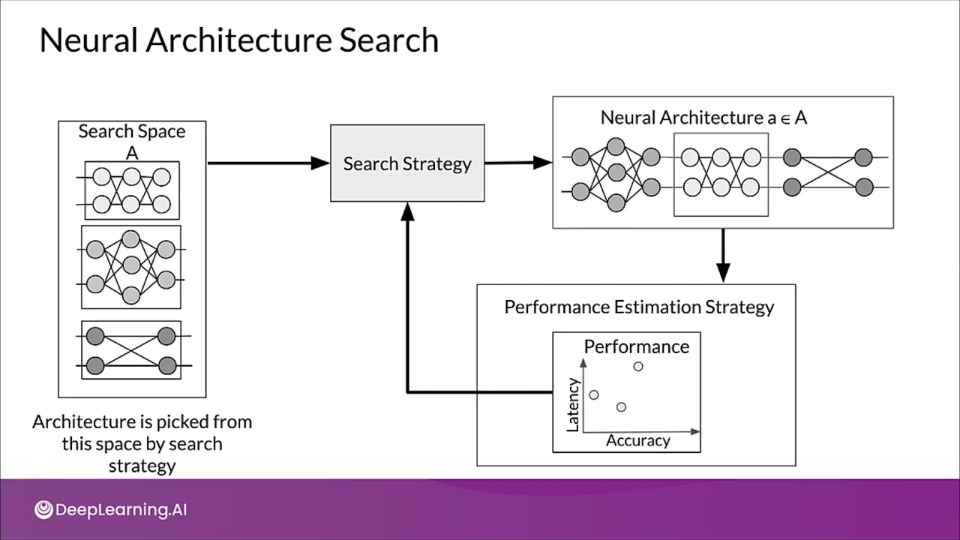
Neural Architecture Search (❤️ of AutoML)
The process of automating architecture engineering is strictly called NAS.
Three main parts:
- Search space: Defines the range of architecture which can be represented.
- Search strategy: Defines how we explore the search space.
- Performance estimation strategy: Helps measure the comparing the performance of various architectures.
Understanding Search Spaces
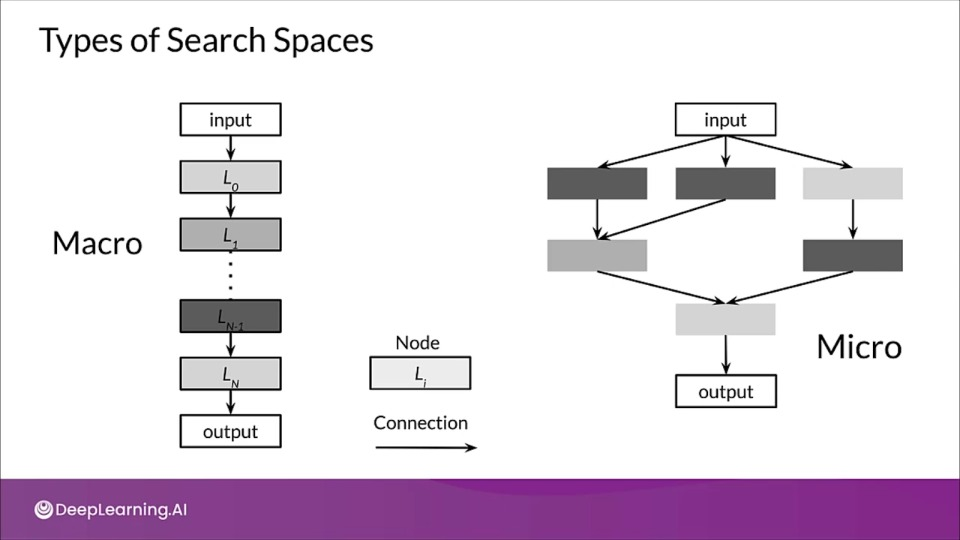
Types of Search Space:
- Macro
- Micro
Node: A node is a layer in a neural network.
An arrow from layer $\text{L}_i$ to $\text{L}_j$ indicates the layer $\text{L}_j$receives the output of $\text{L}_i$as input.
Macro Architecture Search Space
A macro search space contains the individual layers and connection types of neural network.
- A NAS searches within that space for the best model, building the model layer by layer.
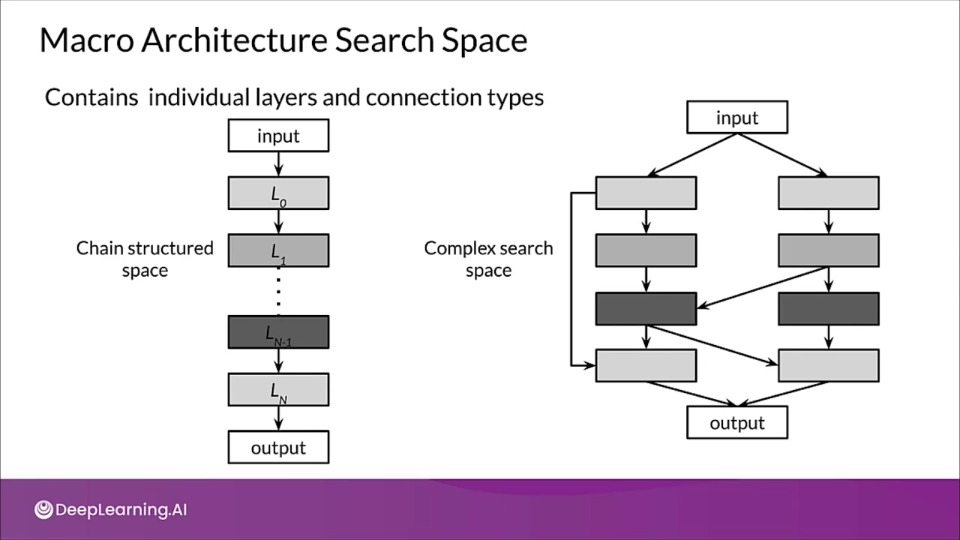
In a chain-structured Neural Network Architecture (NNA), space is parametrized as:
- The operation every layer can execute
- Hyperparameters associated with the operation
- A number of n sequentially fully-connected layers
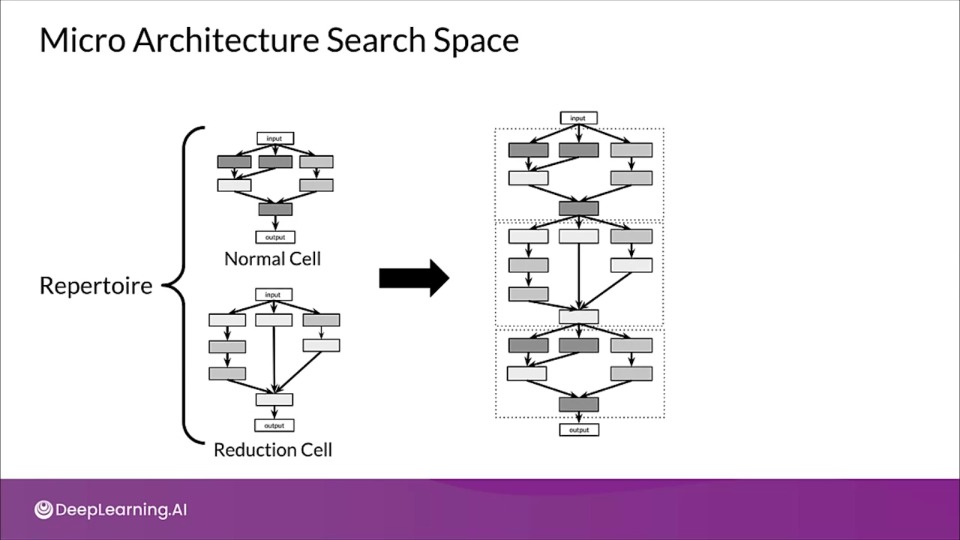
Micro Architecture Search Space
In a micro search space, NAS build a neural network from cells where each cell is a smaller network.
- Cells are stacked to produce the final network.
Search Strategies
- Find the architecture that produces the best performance
A few search strategies
- Grid Search
- Random Search
- Bayesian Optimization
- Evolutionary Algorithms
- Reinforcement Learning
Grid Search & Random Search
Grid Search
- Exhaustive search approach on fixed grid values
Random Search:
- Select the next options randomly within the search space.
Both Suitable for small search space.
Both quickly fail with growing size of search space
Bayesian Optimization
- Assumes that a specific probability distribution, is underlying the performance.
- Tested architectures constrain the probability distribution and guide the selection of the next option.
- This way, promising architectures can be stochastically determined and tested.
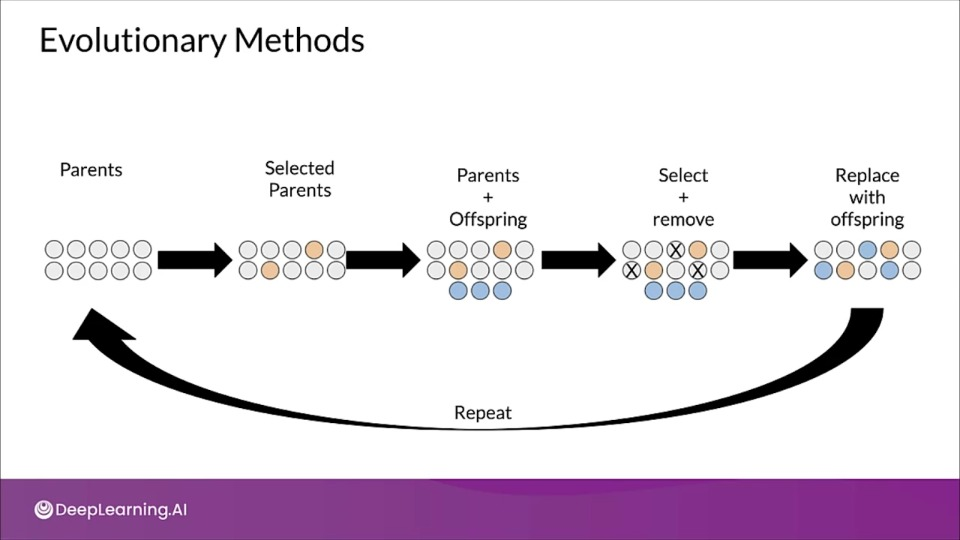
Evolutionary Methods
Reinforcement Learning
- Agents goal is to maximise a reward.
- The available options are selected from the search space.
- The performance estimation strategy determines the reward
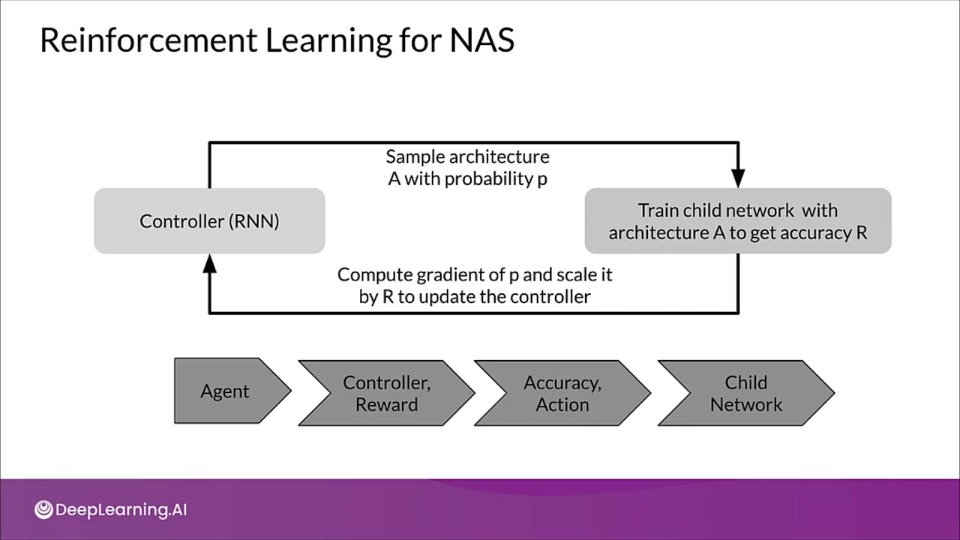
Reinforcement Learning for NAS
- A NN can also be specified by a variable length string.
- Hence RNN can be used generate that string, referred as controller.
- After training model on real data called, child network, we measure the accuracy on validation set.
- This accuracy then determines the reinforcement learning reward.
Neural Architecture Search
Neural Architecture Search
If you wish to dive more deeply into neural architecture search , feel free to check out these optional references. You won’t have to read these to complete this week’s practice quizzes.
Measuring AutoML Efficacy
Performance Estimation Strategy
The search strategies in neural architecture search need to estimate the performance of generated architectures, so that they can in turn generate even better performing architectures.
The simplest approach is to measure validation accuracy...
Strategies to Reduce the Cost
- Lower fidelity estimates
- Learning Curve Extrapolation
- Weight Inheritance/ Network Morphisms
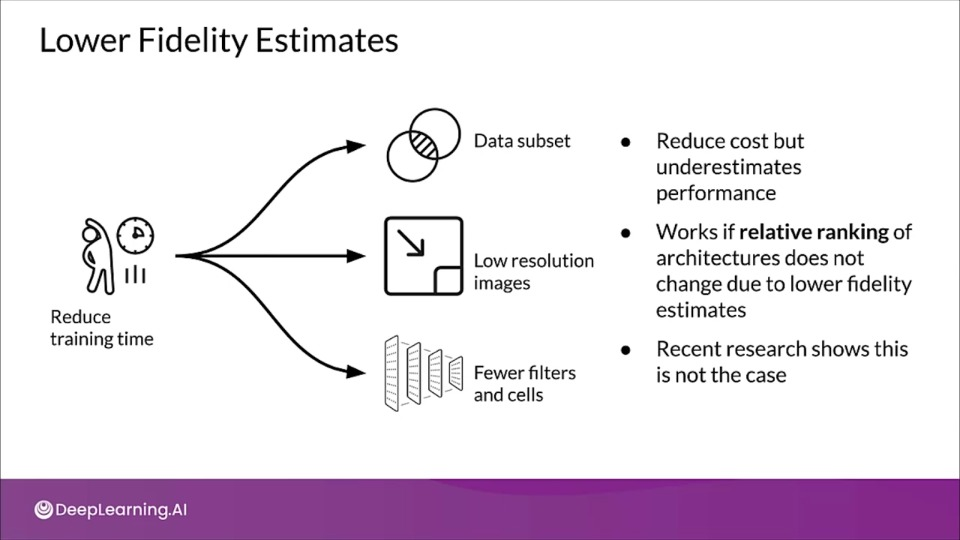
Lower fidelity estiamtes
Lower fidelity or precision estimates try to reduce training time by reframing the problem make is easier to solve.
This is done either by:
- Training on subset of data
- lower resolution images
- Fewer filters per layer and fewer cells
Learning Curve Extrapolation
Based on the assumption that you have mechanisms to predict the learning curve reliably.
- Extrapolates based on initial learning
- Removes poor performers
- Progressive NAS, uses a similar approach by training a surrogate model and using it to predict the performance using architectural properties.
Weight Inheritance/Network Morphisms
- Initialize weights of new architectures based on previously trained architectures.
- Similar to transfer learning
- Uses Network Morphism
- Modifies the architecture without changing the underlying function.
- New network inherits knowledge from parent network
- Computational speed up: only a few days of GPU usage
- Network size not inherently bounded
AutoML on the Cloud
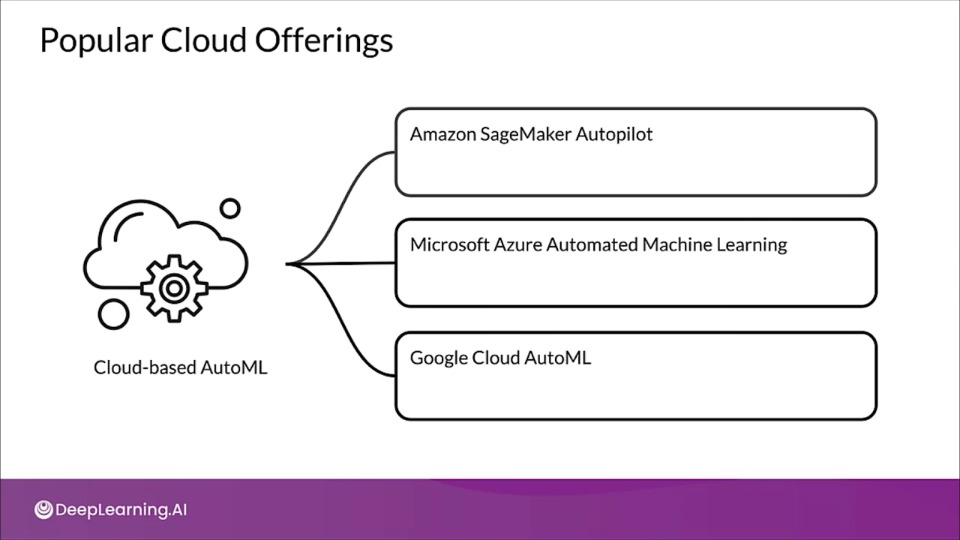
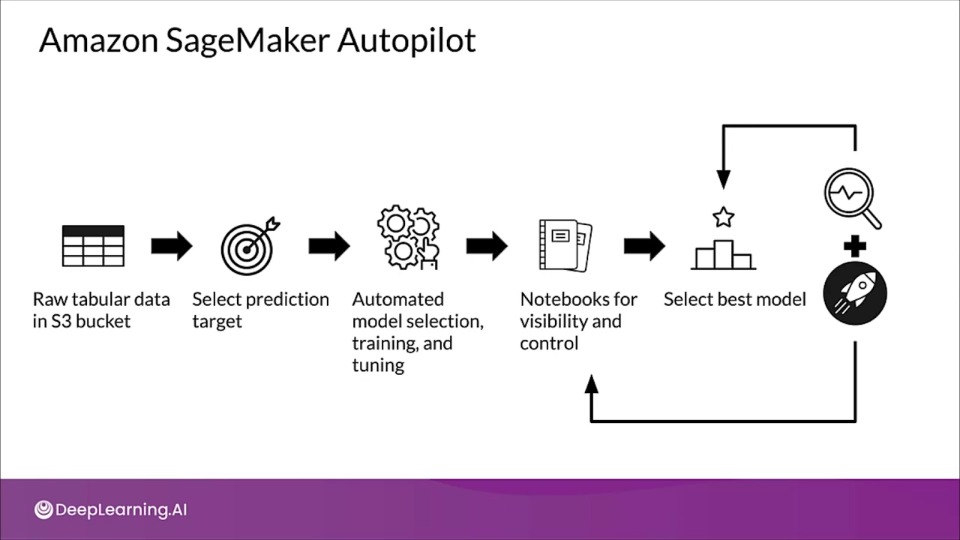
Amazon SageMaker Autopilot
Automatically trains and tunes the model for classification or regression based on your data.
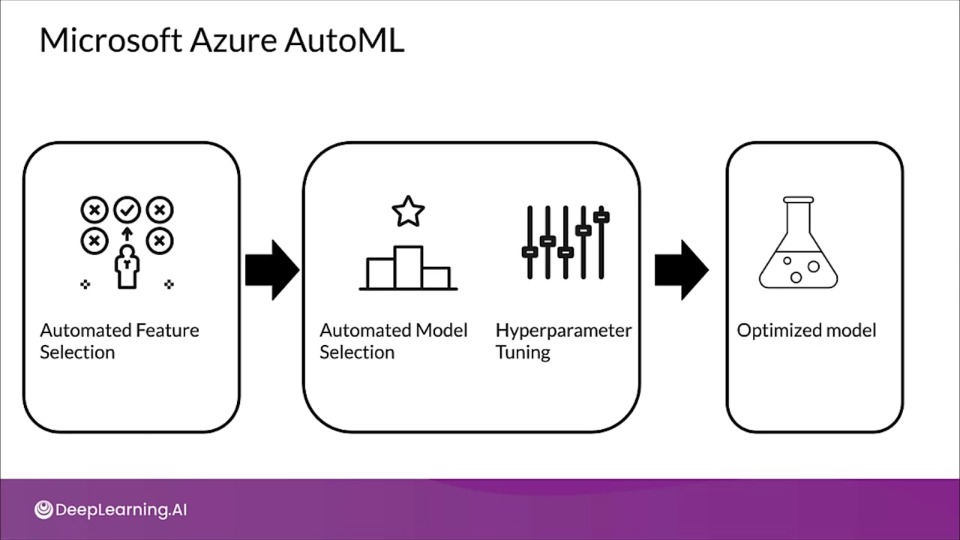
Microsoft Azure AutoML
Google Cloud AutoML
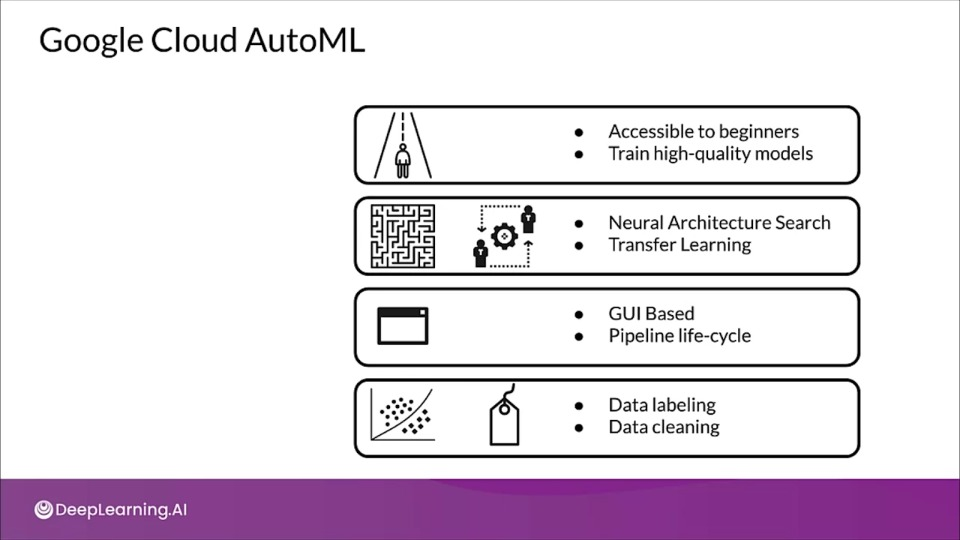



How do these Cloud offerings perform AutoML?
- We don't know (or can't say) and they're not about to tell us.
- The underlying algorithms will be similar to what we've learned.
- The algorithms will evolve with the state of the art
AutoML
AutoML
If you wish to dive more deeply into AutoMLs, feel free to check out these cloud-based tools. You won’t have to read these to complete this week’s practice quizzes.