Week 1 — Intro to Model Serving and Infrastructure
Introduction to Model Serving
What exactly is Serving a Model?
Model Serving Patterns
Components used by inference process:
- A model,
- An interpreter
- Input data
ML worflows
Batch/static Learning: model training is performed offline on a set of already collected data.
Online/Dynamic learning: model is regularly being retrained as new data arrives as is in the case of time series data.
Batch Inference: when the inference is not done instantly and is pushed in a batch to be done.
Realtime Inference: predictions are generated in real time using available data at the time of the request.
Important Metrics
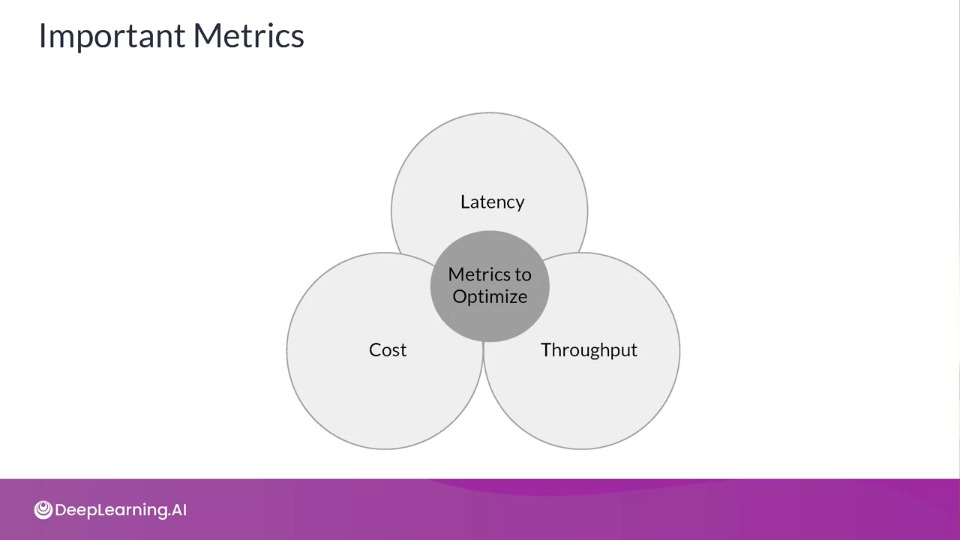
- Latency: Delay between user's action and response of application to user's action. Latency of the whole process, starting from sending data to server, performing inference using model and returning response
Minimal latency is a key requirement to maintain customer satisfaction
-
Throughput: Number of successful requests served per unit time say one second
In some applications only throughput is important and not latency.
-
Cost
The cost associated with each inference should be minimised
Important infrastructure requirements that are expensive:
- CPU
- Hardware Accelerators like GPU
- Caching infrastructure for faster data retrieval
Minimizing latency, Maximising Throughput
Minimizing latency
- Airline Recommendation Service
- Reduce latency for user satisfaction
Maximising Throughput
- Airline recommendation service faces high load of inference requests per second.
Scale infrastructure (number of servers, caching requirements etc.) to meet requirements
Balance Cost, Latency and Throughput
- Cost increases as infrastructure is scaled
- In applications where latency and throughput can suffer slightly:
- Reduce costs by GPU sharing
- Multi-model serving etc..,
- Optimizing models used for inference
Introduction to Model Serving Infrastructure
Optimizing Models for Serving
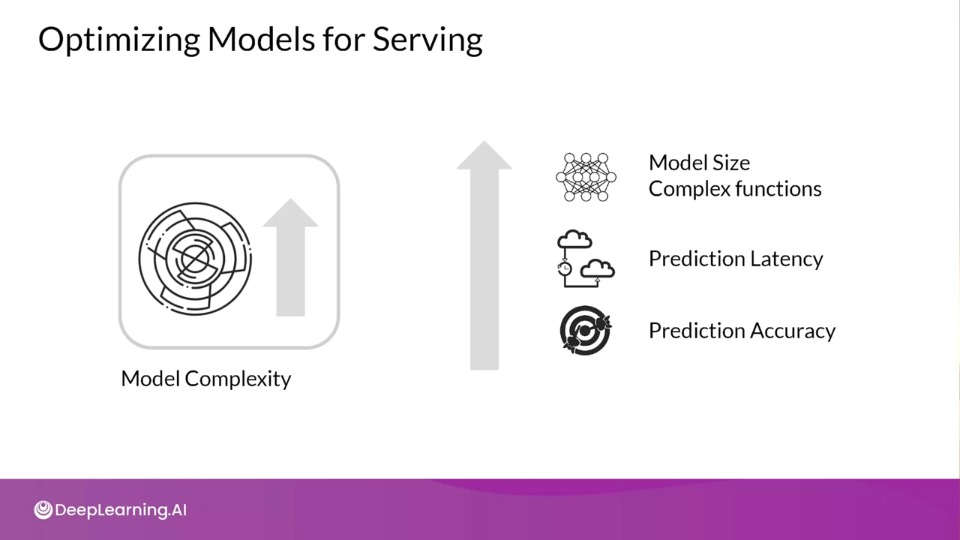
As Model Complexity Increases Cost Increases
Increased requirements means Increased cost and increases hardware requirement management of larger model registries leading to higher support and maintenance burden.
Balancing Cost and Complexity
The challenge for ML practitioners is to balance complexity and cost
Optimizing and Satisficing Metrics

Use of Accelerators in Serving Infrastructure
Maintaining Input Feature Lookup
- Prediction request to your ML model might not provide all features required for prediction
- For example, estimating how long food delivery will require accessing features from a data store:
- Incoming orders (not included in request)
- Outstanding orders per minute in the past hour
- Additional pre-computed or aggregated features might be read in real-time form a data store.
- Providing that data store is a cost
NoSQL Databases: Caching and Feature Lookup
Google Cloud Memorystore: In memory cache, sub-millisecond read latency
Google Cloud Firestore: Scaleable, can handle slowly changing data, millisecond read latency
Google Cloud Bigtable: Scaleable, handles dynamically changing data, millisecond read latency
Amazon DynamoDB: Single digit millisecond read latency, in memory cache available.
Deployment Options
Two options:
- Data centers
- Embedded devices
Running in Huge Data Centers
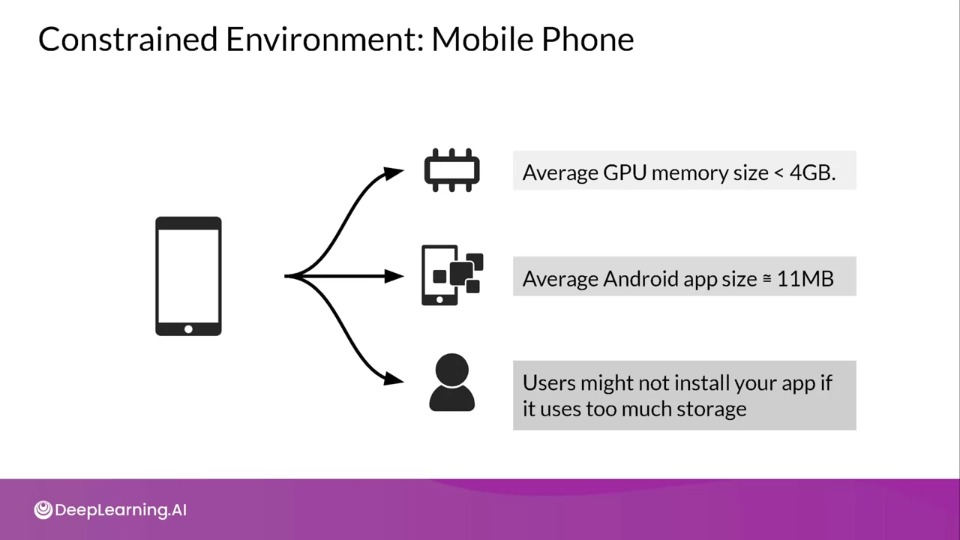
Constrained Environment: Mobile Phone
Restrictions in a Constrained Environement
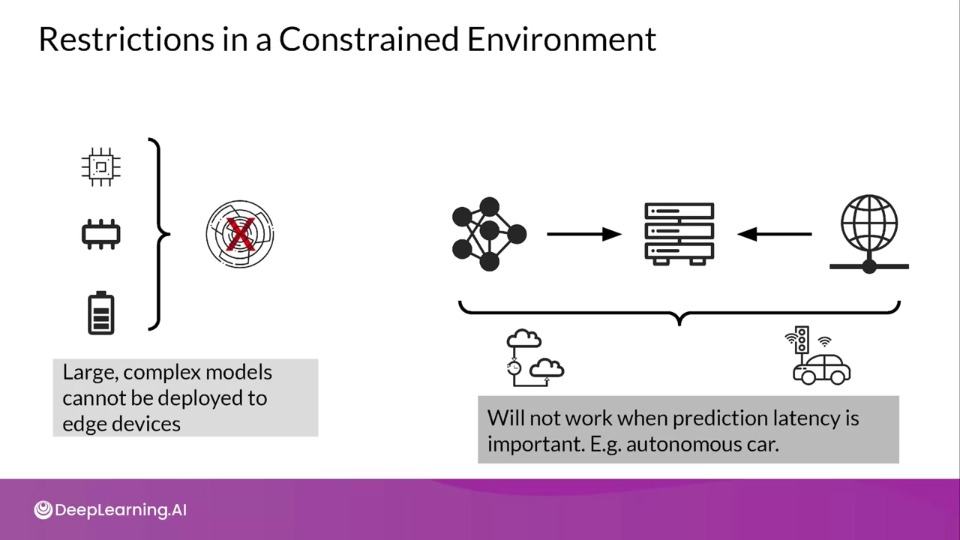
Prediction Latency is Almost Always Important
- Opt for on-device inference whenever possible
- Enhances user experience by reducing the response time of your app
Improving Prediction Latency and Reducing Resource Costs
For mobile deployed models
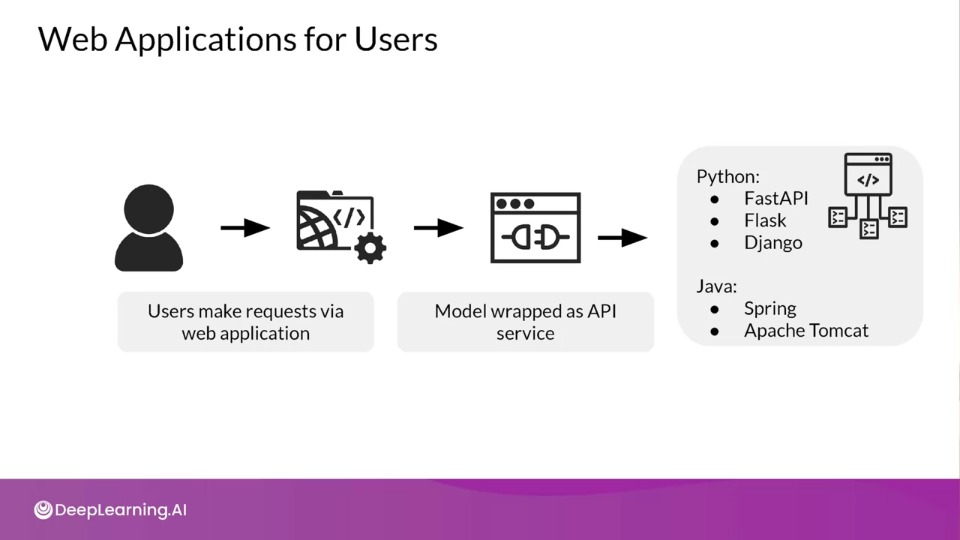
Web Applications for Users
Serving systems for easy deployment
- Centralized model deployment
- Predictions as service
Eliminates need for custom web applications by getting the mode deployed in just a few lines of code. They can also make is easy to rollback/update models on the fly.
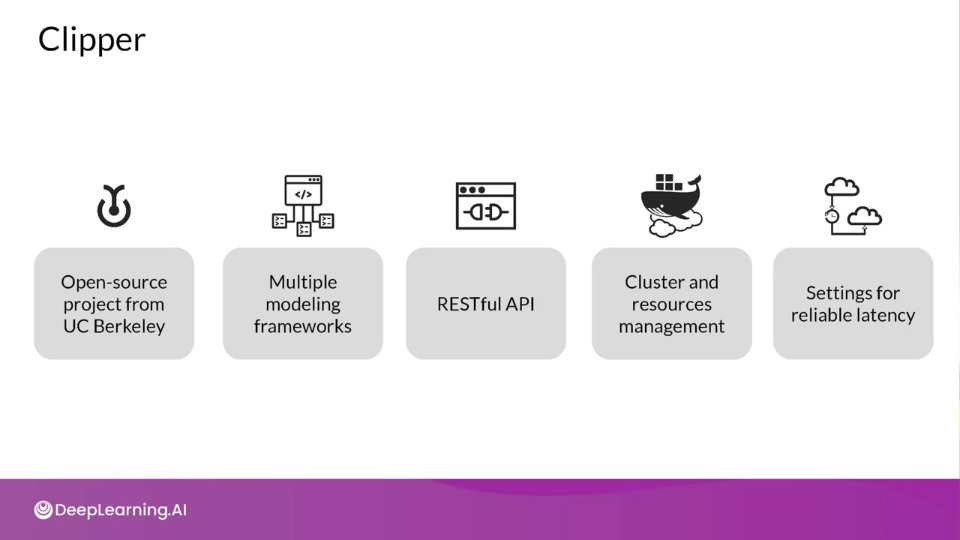
Clipper
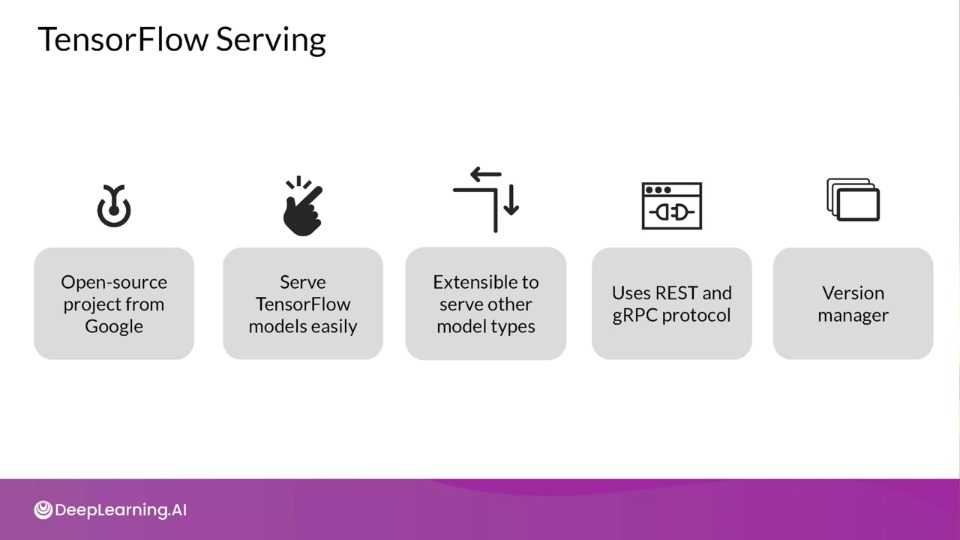
TensorFlow Serving
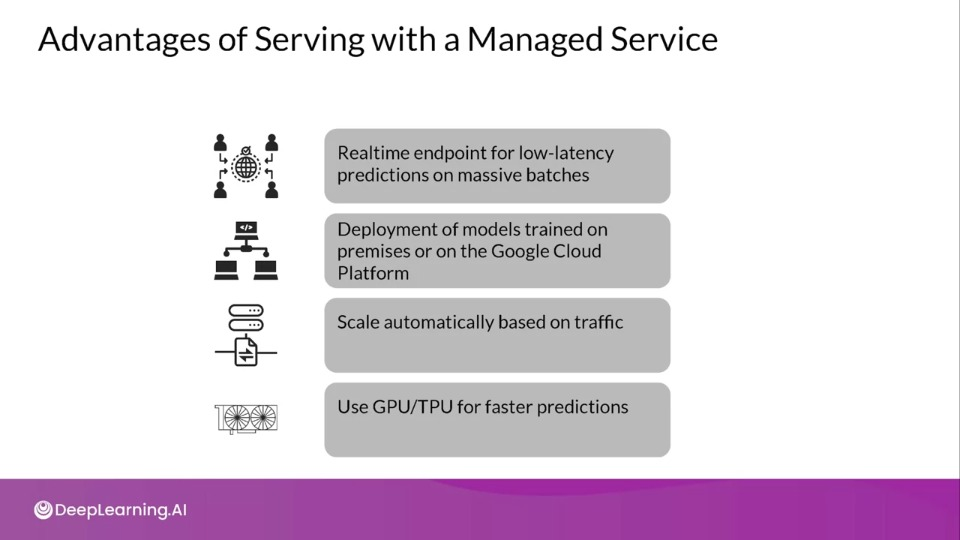
Advantages of Serving with a Managed Service
Installing TensorFlow Serving
-
Docker Image:
- Easiest and most recommended method
Install TensorFlow Serving

- Building From Source
- Install using Aptitude (
apt-get) on a Debian-based Linux system
!echo "deb http://storage.googleapis.com/tensorflow-serving-apt stabletensorflow-model-server tensorflow-model-server-universal" |
tee /etc/apt/source.list.d/tensorflow-serving.list && \
curl https://storage/googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | apt-key add -
!apt update
!apt-get install tensorflow-model-server
Import the MNIST Dataset
mnist = tf.keras.datasets.mnist
(train_image, train_labels), (test_images, test_labels) = mnist.load_data()
# Scale the values of the arrays below to be between 0.0 and 1.0
train_images = train_images / 255.0
test_images = test_images / 255.0
# Reshape the arrays below
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1)
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1)
print("\ntrain_images.shape: {}, of {}".format(
train_images.shape train_images.dtype))
print("test_images.shape: {}, of {}".format(
test_images.shape test_images.dtype))
Look at a sample Image
idx = 42
plt.imshow(test_images[idx].reshape(28, 28), cmap=plt.cm.binary)
plt.title("True label: {}".format(test_labels[idx]), fontdict={'size': 16})
plt.show()
Build a Model
# Create a model
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(
input_shape=(28, 28, 1),
filters=8, kernel_size=3,
strides=2, activation='relu',
name='Conv1'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation=tf.nn.softmax, name='softmax')
])
model.summary()
Train the Model
# Configure the model for training
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
epochs=5
hisory = model.fit(train_images, train_labels, epochs=epochs)
Evaluate the Model
# evaluate the model on the test iamges
results_eval = model.evaluate(test_images, test_labels, verbose=0)
for metric, value in zip(model.metrics_names, results_eval):
print(metric + ': {:.3}'.format(value))
Save the Model
MODEL_DIR = tempfile.gettempdir()
version = 1
export_path = os.path.join(MODEL_DIR, str(version))
if os.path.isdir(export_path):
print('\n Already saved a model, clearning up\n')
!rm -r {export_path}
model.save(export_path, save_format='tf')
print('\nexport_path = {}'.format(export_path))
!ls -l {export_path}
Launch Your Saved Model
os.environ['MODEL_DIR'] = MODEL_DIR
%%bash --bg
nohup tensorflow_model_server \
--rest_apt_port=8501 \
--model_name=digits_model \
--model_base_path="${MODEL_DIR}" > server.log 2>&1
!tail server.log
Sending an Inference Request
data = json.dumps({
"signature_name": "serving_default",
"isntances": test_images[0:3].tolist()})
headers = {"content-type": "application/json"}
json_response = requests.post(
'https://localhost:8501/v1/models/digits_model:predict',
data=data, headers=headers)
predictions = json.loads(json_response.text)['predictions']
Plot Predictions
plt.figure(figsize=(10, 15))
for i in range(3):
plt.subplot(1, 3, i+1)
plt.imshow(test_iamges[i].reshape(28, 28), cmap=plt.cm.binary)
plt.axis('off')
color = 'green' if np.argmax(predictions[i]) == test_labels[i] else 'red'
plt.title('Prediction: {}\n True Label: {}'.format(
np.argmax(predictions[i]),
test_labels[i]), color=color)
plt.show()