Week 3 — Data Journey
Data Storag -- Data Journey
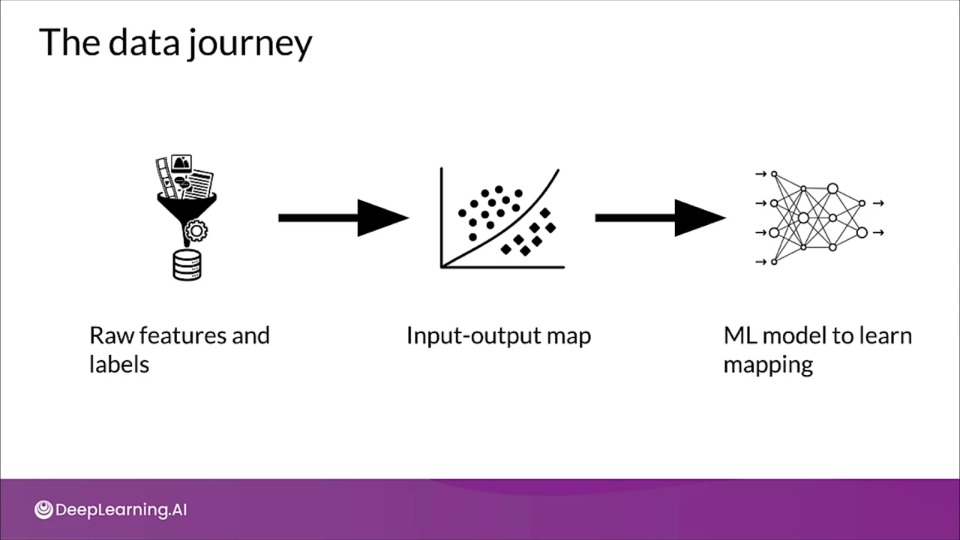
- Data transforms as it flows through the process
- Interpreting model results requires understanding data transformation
Artifacts and the ML pipeline
- Artifacts are created as the component of the ML pipeline execute
- Artifacts include all of the data and objects which are produced by the pipeline components.
- This includes the data, in different stages of transformation, the schema, the model itself, metrics, etc.
Data provenance and lineage
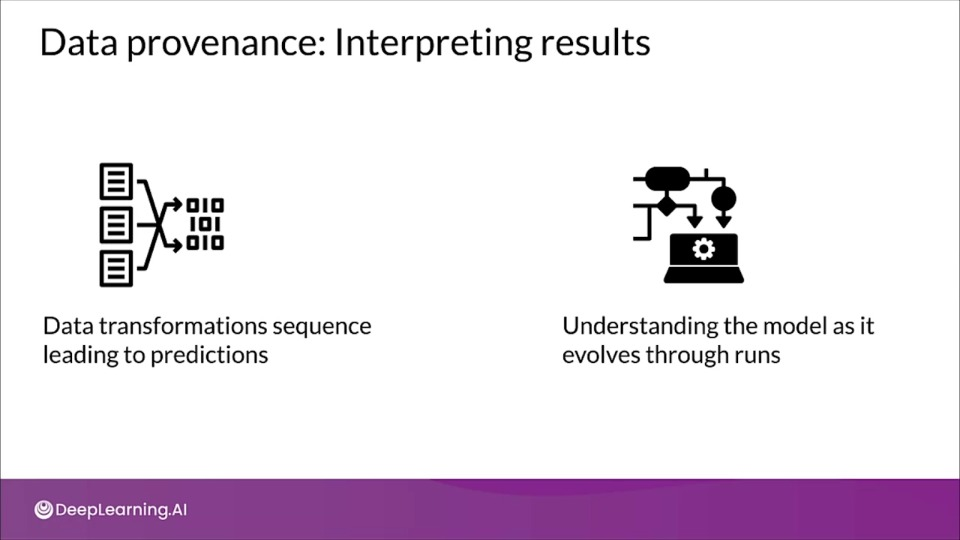
- The chain of transformations that led to the creation of a particular artifact
- Important for debugging and reproducibility.

Data lineage: data protection regulation
- Organizations must closely track and organize personal data
- Data lineage is extremely important for regulatory compliance
Data versionining
- Data pipeline management is a major challenge
- Machine learning requires reproducibility
- Code versioning: GitHub and similar code repositories
- Environment versioning: Docker, Terraform, and similar
- Data versioning:
- Version control of datasets
- e.g., DVC, Git-LFS
Introduction to ML Metadata
- Every run of a production ML pipeline generates metadata containing information about the various pipeline components, their executions and the resulting artifacts.
![]()
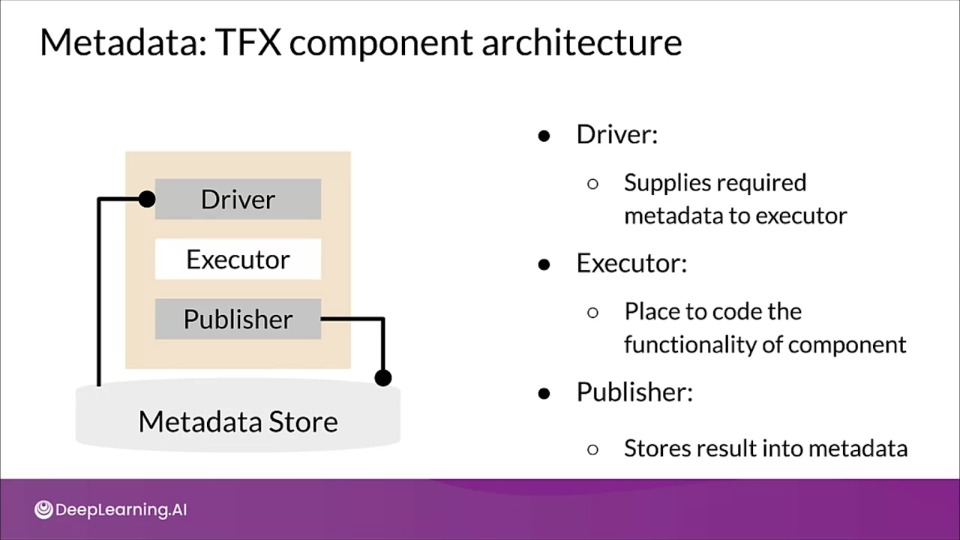
ML Metadata library
- Tracks metadata flowing between components in pipeline
- Supports multiple storage backends
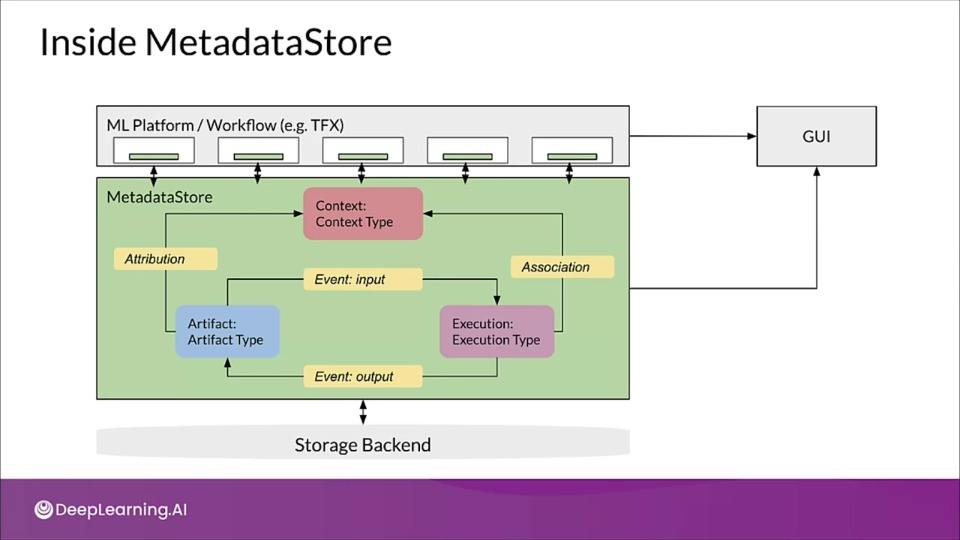
ML Metadata terminology
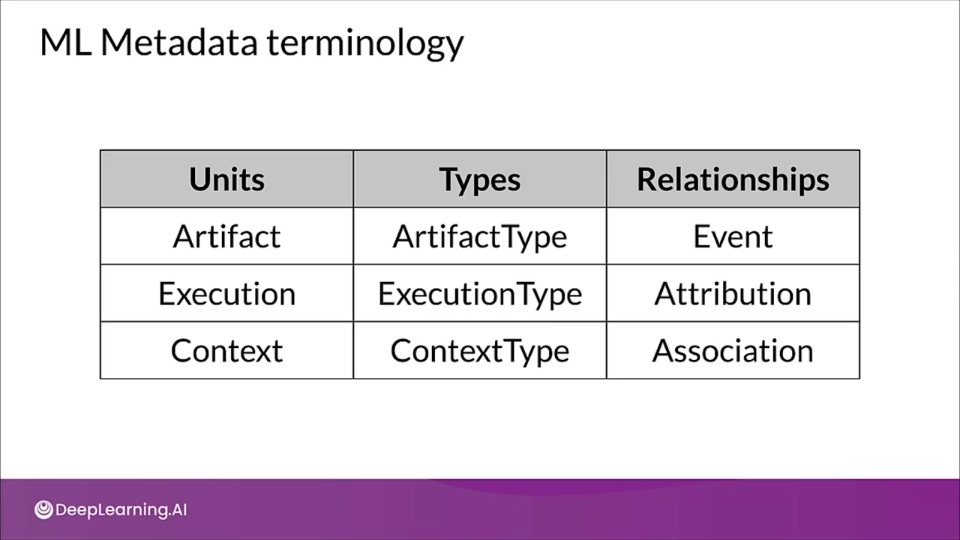
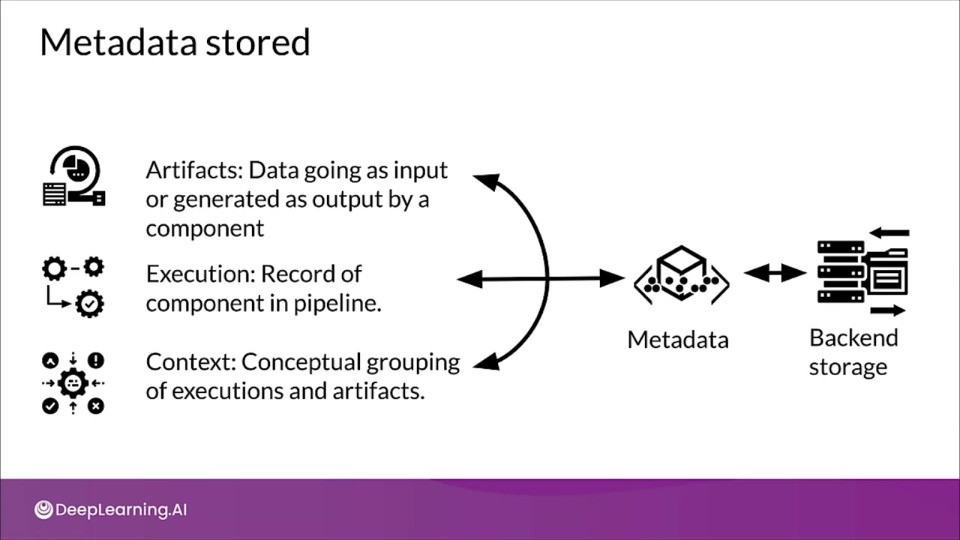
Artifact: An artifact is an elementary unit of data that gets fed into the ML metadata store and as the data is consumed as input or as generated as output of each component.
Execution: Each execution is a record of any component run during the ML pipeline workflow, along with its associated runtime parameters.
Context: A context may hold the metadata of the projects being run, experiments being conducted, details about pipeline, etc. It captures the shared information within the group. For example: project name, changelist commit id, experiment annotations etc. Artifacts and executions can be clustered together for each type of component separately.
- Each units can be of several different types having different properties stored in ML metadata.
- Relationships store the various units getting generated or consumed when interacting with other units.
- Like Event is the record of a relationship between an artifact and an execution.
Metdata Stored
Inside MetadataStore
ML MetaData in Action

!pip install ml-metadata
from ml_metadata import metadata_store
from ml_metadata.proto import metadata_store_pb2
ML Metadata storage backend
- ML metadata registers metadata in a database called Metadata Store
- APIs to record and retrieve metadata to and from the storage backend
- Fake database: in-memory for fast experimentation/prototyping
- SQLite: in-memory and disk
- MySQL: server based
- Block storage: File system, storage area network, or cloud based
Fake database
connection_config = metadata_store_pb2.ConnectionConfig()
# Set an empty fake database proto
connection_config.fake_database.SetInParent()
store = metadata_store.MetadataStore(connection_config)
SQLite
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connnection_config)
MySQL
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connnection_config)
Schema Development
Schema are relational objects summarizing the features in a given dataset or project. This includes:
- Feature name
- Type: float, int, string, etc
- Required or optional
- Valency (feature with multiple values)
- Domain: range, categories
- Default values
Reliability during data evolution
Your system and your development process must treat data errors as first-class citizens, just like code bugs.
Iteratively update and fin-tune schema to adapt to evolving data
Platform needs to resilient to disruptions from:
- inconsistent data
- pipeline needs to gracefully handle software generated errors
- user misconfigurations
- uneven execution environments
Scalability during data evolution
Anomaly detection using Data evolution
Schema inspection during data evolution
Schema Environments
- You my have different schema versions for different environments, like development and testing.
Maintaining varieties of schema
Inspect anomalies in serving dataset
stats_options = tfdv.StatsOptions(schema=schema,
infer_type_from_schema=True)
eval_stats = tfdv.generate_statistics_from_csv(
data_location=SERVING_DATASET,
stats_options=stats_options
)
serving_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(serving_anomalies)
Schema environments
- Customize the schema for each environment
- e.g., Add or remove label in schema based on type of dataset
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Modify serving environment feature,
# removing from 'SERVING' environment as it will not be there
tfdv.get_feature(schema, 'Cover_Type').not_in_environment.append('SERVING')
Now Inspecting anomalies will return no anomalies
serving_anomalies = tfdv.validate_statistics(
eval_stats,
schema,
environment='SERVING')
tfdv.display_anomalies(serving_anomalies)
# No anomalies found
Enterprise Data Storage — Feature Stores
A feature store is a central repository for storing documented, curated and access controlled features.
A feature store make it easy for different teams to share, discover and consume highly curated features. Many modelling problems might use identical or similar features across organization, thus having a feature store greatly reduces redundant work. This also enables teams to share and discover data.
Key aspects
- Managing feature data from a single person to large enterprises
- Scalable and performant access to feature data inn training and serving.
- Provide consistent and point-in-time correct access to feature data.
- Enable discovery, documentation, and insights into your features.

Data Warehouse
Data warehouse is a technology that aggregates data from one or more sources so that it can be processed and analyzed. It's optimized for long running batch jobs and read operations. They are not designed to placed in a production environment.
Key features of data warehouse
- A data warehouse is subject oriented and information stored in it revolves around a topic.
- The data might be collected from various types of sources, like RDBMS, files etc.,
- Non-volatile, previous versions of data is not erased when new data is added
- Time variant, can let you go through timestamped data.
Advantages
- Enhanced ability to analyze the data, without worrying about serving performance degradation.
- Timely access to data
- Enhanced data quality and consistency
- High return on investment
- Increased query and system performance
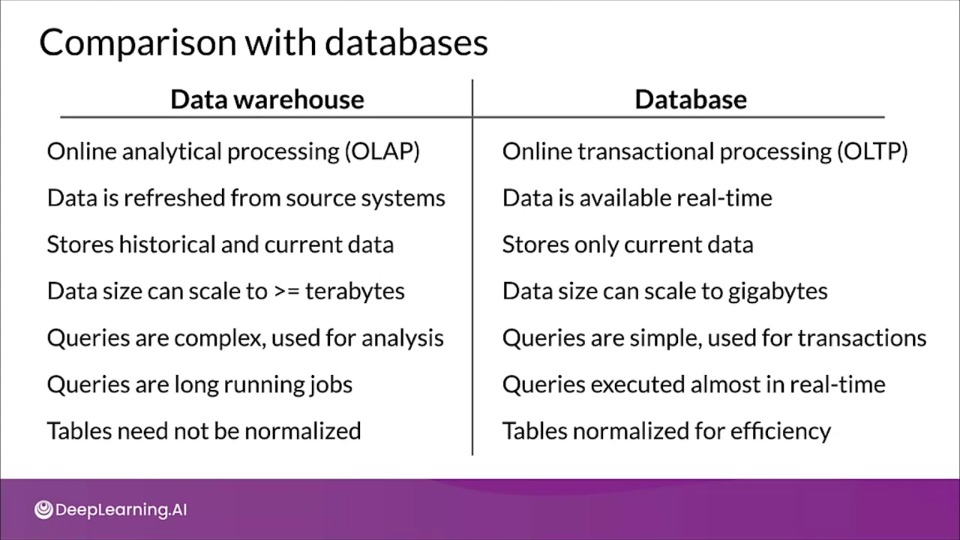
Comparison with databases
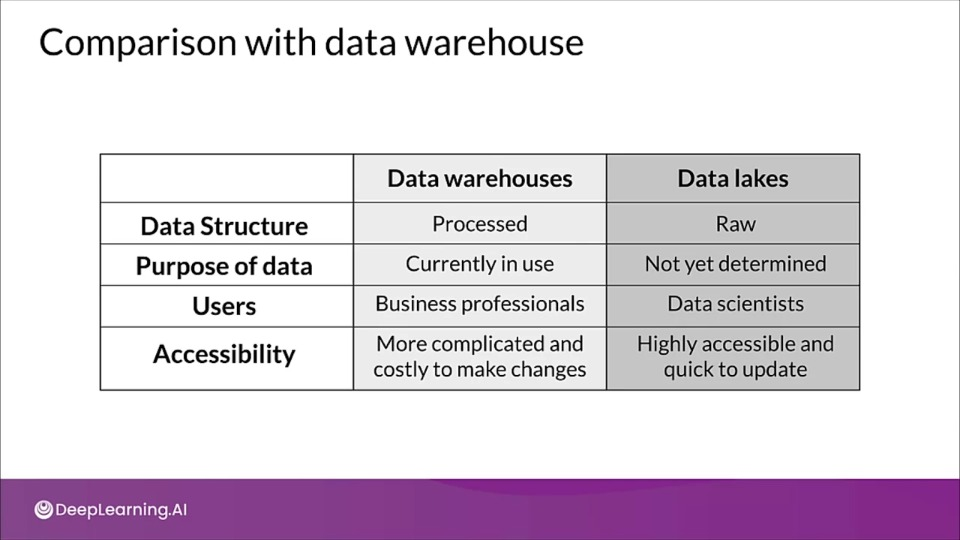
Data Lakes
A data lake is a system or repository of data stores in its natural and raw format.
- A data lake, like warehouse aggregates data from various sources of enterprise data
- Data can be structured or unstructured
- Doesn't involve any processing before writing data, don't have schema
Week 3 References
Week 3: Data Journey and Data Storage
If you wish to dive more deeply into the topics covered this week, feel free to check out these optional references. You won’t have to read these to complete this week’s practice quizzes.
Data Versioning:
ML Metadata:
- https://www.tensorflow.org/tfx/guide/mlmd#data_model
- https://www.tensorflow.org/tfx/guide/understanding_custom_components
Chicago taxi trips data set:
- https://data.cityofchicago.org/Transportation/Taxi-Trips/wrvz-psew/data
- https://archive.ics.uci.edu/ml/datasets/covertype
Feast: