Week 1 — Collecting, labeling, and validating data
Overview
This course is all about data, the first week we'll go through collecting our data, labeling it, and validating it. Along the way we'll also get familiarize with TensorFlow Extended (TFX) framework and data pipelines.
"Data is the hardest part of ML and the most important piece to get right...broken data is the most common cause of problems in production ML systems" - Scaling Machine Learning at Uber with Michelangelo - Uber

The production setting for ML systems is really different than academic one where the data is fixed, already cleaned and ready to be experimented with.
Success
Production ML = ML development + software development
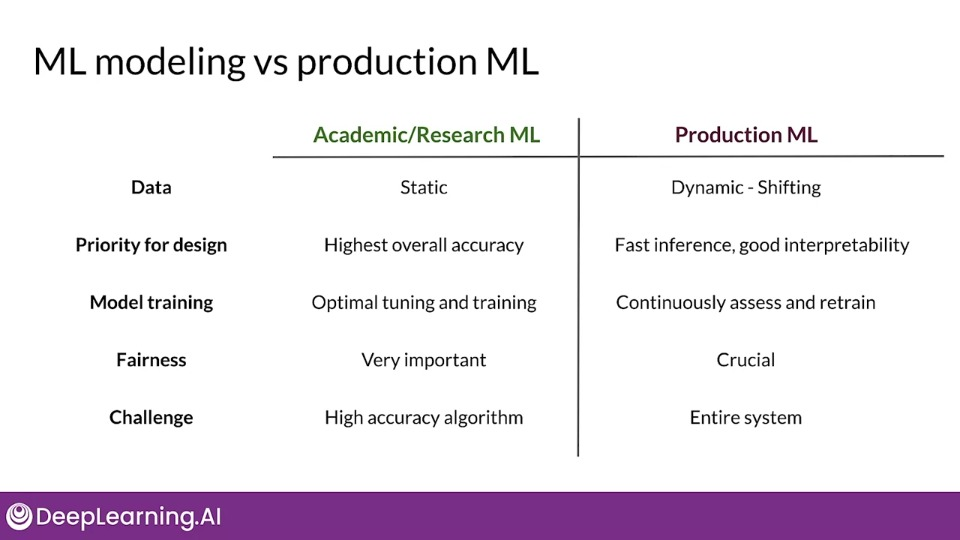
Using Modern software development also needs to account for:
- Scalability,
- Extensibility
- Configuration
- Consistency & reproducibility
- Best practices
- Safety & security
- Modularity
- Testability
- Monitoring
Challenges in production grade ML
- Build integrated ML systems
- Continuously operate it in production
- Handle continuously changing data
- Optimize compute resource costs
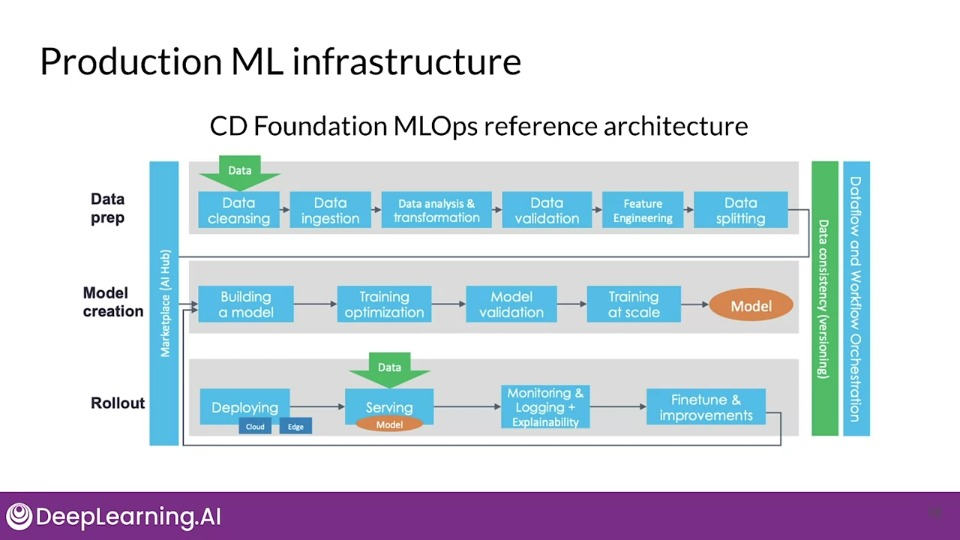
ML pipelines
ML pipeline is a software architecture for automating, monitoring, and maintaining the ML workflow from data to a trained model.
A directed acyclic graph (DAG) is a directed graph that has no cycles.
ML pipeline workflow are usually DAGs,
Pipeline orchestration frameworks are responsible for the various components in an ML pipeline depending on DAG dependencies. Basically help with pipeline automation.
Examples: Airflow, Argo, Celery, Luigi, Kubeflow
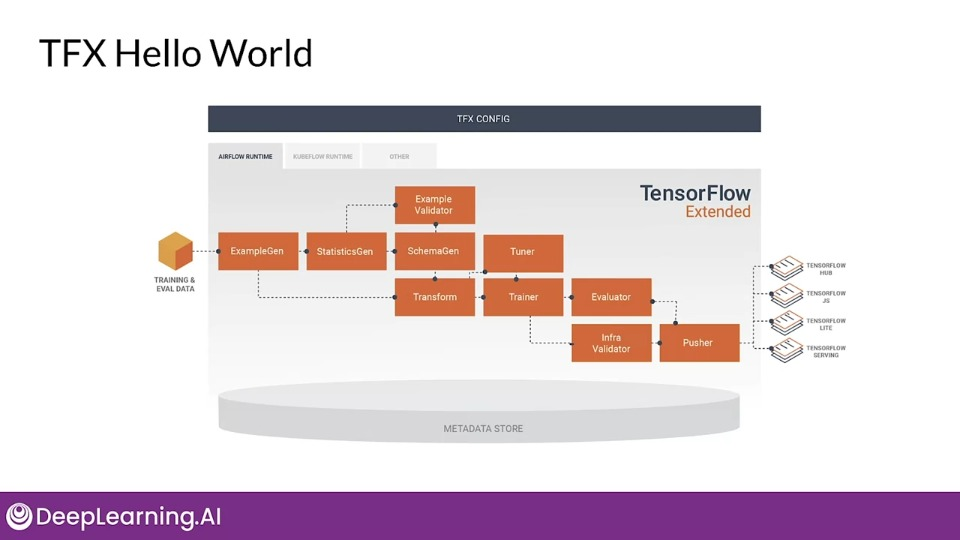
TensorFlow Extended (TFX)
End-to-end platform for deploying production ML pipelines.
TFX production components are designed for scalable, high-performance machine learning tasks.
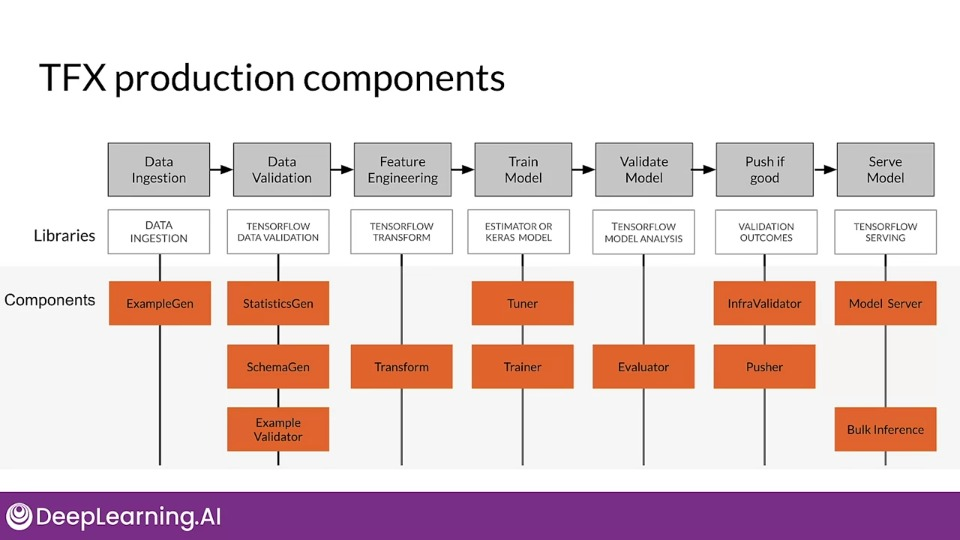 tion="Components represented by orange blocks." >}}
tion="Components represented by orange blocks." >}}
Collecting Data — Importance of Data
In ML arena Data is a first class citizen.
- Software 1.0: Explicit instructions were given to the computer
- Software 2.0:
- Specify some goal on the behaviour of a program
- Find solution using optimization techniques.
- Good data is key for success
- Code in Software = Data in ML
Models aren't magic wands, they are statistical tools and so require meaningful data:
- Maximize predictive content
- remove non-informative data
- feature space coverage
Key Points
- Understand users, translate user needs into data problems
- What kind of/how much data is available
- What are the details and issues of your data
- What are your predictive features
- What are the labels you are tracking
- What are your metrics
- Ensure data coverage and high predictive signal
- Source, store and monitor quality data responsibly
Few issues while collecting data that may arise:
- Inconsistent formatting
- Is zero "0", "0.0", or an indicator of a missing measurement, sea level, bad sensor?
- Compounding errors from other ML models
- Monitor data sources for system issues and outages
- Outliers
Measure data effectiveness
- Intuition about data value can be misleading
- Which feature have predictive value and which ones do not?
- Feature engineering helps to maximise the predictive signals
- Feature selection helps to measure the predictive signals
Responsible Data: Security, Privacy & Fairness
- Data collection and management isn't just about your model
- Give user control of what data can be collected
- Is there a risk of inadvertently revealing user data?
- Compliance with regulations and policies (e.g. GPDR)
Data privacy is proper usage, collection retention, deletion and storage of the data.
- Protect personally identifiable information
- Aggregation - replace unique values with summary value
- Redaction - remove some data to create less complete picture
Commit to fairness
- Make sure your models are fair
- Group fairness, equal accuracy
- Bias in human labeled and/or collected data.
- ML models can amplify biases.
Reducing bias: Design fair labelling systems
- Accurate labels are necessary for supervised learning
- Labeling be done by
- Automation (logging or weak supervision)
- Humans (aka "Raters", often semi-supervised)
How ML systems can fail users
- Representational harm: A system will amplify or reflect a negative stereotype about particular groups.
- Opportunity denial: When a system makes predictions that have negative real life consequences that could result in lasting impacts.
- Disproportionate product failure: Where the effectiveness of your model is really skewed so that the output happen more frequently for particular groups of users, skewed outputs are generated.
- Harm by disadvantage: A system will infer disadvantageous associations between different demographic characteristics and user behaviour around that.
Types of human raters
- Generalists (usually by crowdsourcing tools)
- Subject Matter Experts (requires specialized tools, like X-Rays)
- Your users (Derived labels, e.g. tagging photos.
Key points
- Ensure rater pool diversity
- Investigate rater context and incentives
- Evaluate rater tools
- Manage cost
- Determines freshness requirements
Labeling data — Data and Concept Change in Production ML
Detecting problems with deployed models
- Data and scope changes
- Monitor models and validate data to find problems early
-
Changing ground truth: label new training data
The ground truth may change gradually (may be years, months) or faster (weeks) or maybe really really fast (days, hours, min). If the ground truth is changing really fast, you got a really hard problem and might be important to retrain ASAP after following a Direct feedback or Weak supervision.
Key points
- Model performance decays over times
- Data and concept drift
- Model retraining helps to improve performance
- Data labeling for changing ground truth and scarce labels
Process Feedback and Human Labeling
Methods
- Process Feedback (Direct Labeling): e.g., Actual vs predicted click-through
- Human Labeling: e.g., Cardiologists labeling MRI images
- Semi-Supervised Labeling
- Active Learning
- Weak Supervision
Why is labeling important in production ML?
- Using business/organisation available data
- Frequent model retraining
- Labeling ongoing and critical process
- Creating a training datasets requires labels
Direct labeling — continuous creation of training dataset
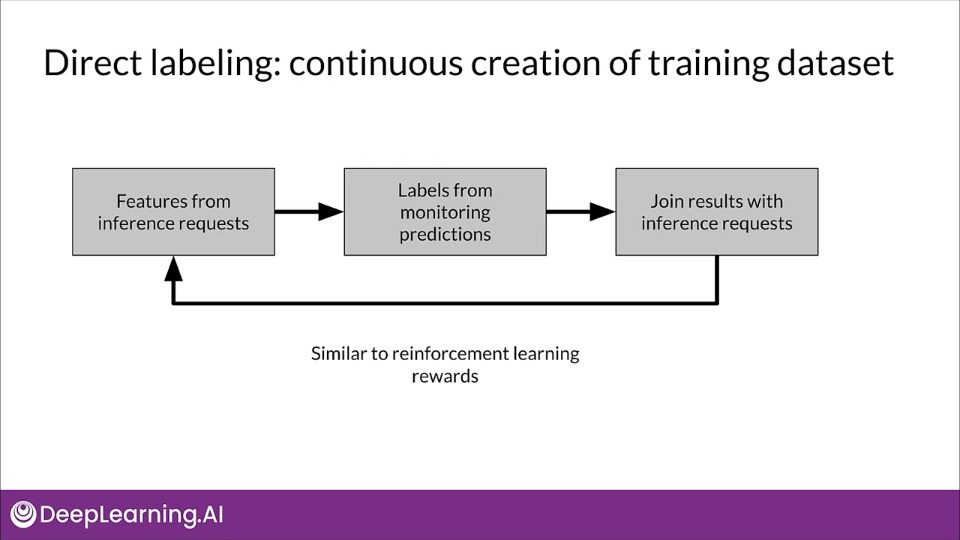
Advantages:
- Training dataset continuous creation
- Labels evolve quickly
- Captures strong label signals
Disadvantages:
- Hindered by inherent nature of the problem
- Failure to capture ground truth
- Largely custom designed
Open-Source log analysis tools
Logstash: Free and open source data processing pipeline
- Ingests data from a multitude of sources
- Transforms it
- Sends it to your favourite "stash"
Fluentd: Open source data collector
Unify the data collection and consumption
Cloud log analytics
Google Cloud Logging
- Data and events from Google Cloud and AWS
- BindPlane. Logging: application components, on-premise and hybrid cloud systems
AWS ElasticSearch
Azure Monitor
Human labeling
"Raters" examine data and assign labels manually

- More labels
- Pure supervised learning
Disadvantages:
- Quality consistency- many datasets difficult for human labeling
- Slow
- Expensive
- Small dataset curation
Validating Data — Detecting Data issues
Concept Drift: Is the change in the statistical properties of the labels over time. The mapping from $x\rightarrow y$ changes
Data Drift: Changes in data over time, such as data collected once a day. The distribution of the data ($x$) changes
Data skew: Difference between two static versions, or different sources, such as training set and serving set.
Detecting distribution skew
Dataset shift occurs when the joint probability of $x$ (features), $y$ (labels) is not same during training and serving.
$$ P_\text{train}(y,x) \not = P_\text{serve}(y, x) $$
Covariate shift refers to the change in distribution of input variables present in training and serving data.
Marginal distribution/probability of features is not the same during training and serving.<
$$ P_\text{train}(y|x) = P_\text{serve}(y|x) \P_\text{train}(x) \not = P_\text{serve}(x) $$
Concept shift refers to a change in the relationship between the input and output variables as opposed to the differences in the Data Distribution or input itself./mark>
$$ P_\text{train}(y|x) \not = P_\text{serve}(y|x)\P_\text{train}(x) = P_\text{serve}(x) $$
Skew detection workflow
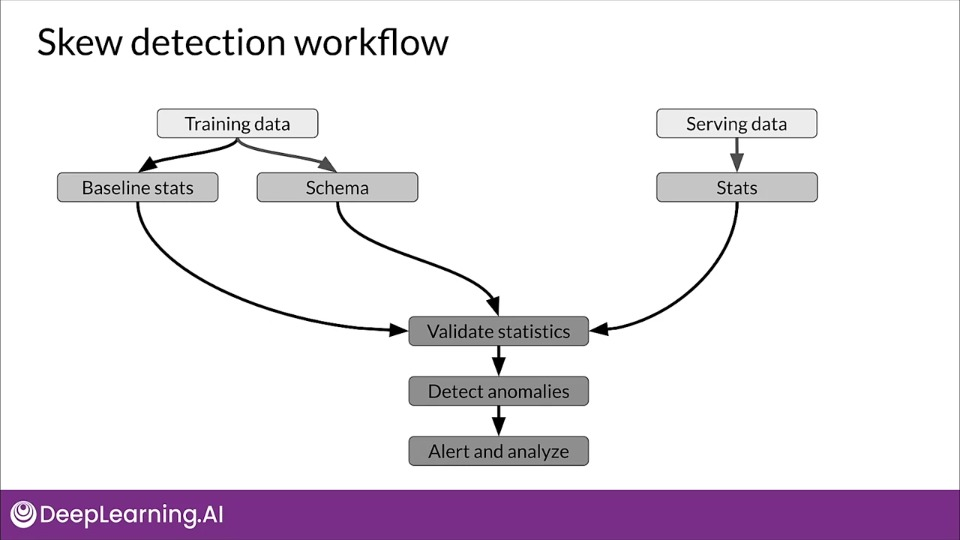
TensorFlow Data Validation (TFDV)
- Understand, validate and monitor ML data at scale
- Used to analyze and validate petabytes of data at Google every day
- Proven track record in helping TFX users maintain the health of their ML pipelines
TFDV capabilities
- Generates data statistics and browser visualizations
- Infers the data schema
- Performs validity checks against schema
- Detects training/serving skew
- Schema skew
- Feature skew
- Distribution skew
Skew - TFDV
- Supported for categorical features
- The Degree of data drift is expressed in terms of L-infinity distance (Chebyshev Distance):
$$ D_\text{Checbyshev}(x, y) = \max_i(|x_i - y_i|) $$
- Set a threshold to receive warnings
Schema skew
Serving and training data don't conform to same schema:
- For example,
int != float
Feature skew
Training feature values are different than the serving feature values:
- Feature values are modified between training and serving time
- Transformation applied only in one of the two instances
Distribution skew
Distribution of serving and training dataset is significantly different:
- Faulty sampling method during training
- Different data source for training and serving data
- Trend, seasonality, changes in data over time
Key points
TFDV: Descriptive statistics at scale with the embedded facets visualizations
It provides insight into:
- What are the underlying statistic of your data
- How does your training, evaluation, and serving dataset statistics compare
- How can you detect and fix data anomalies
Week 1 references
Week 1: Collecting, Labeling and Validating Data
This is a compilation of optional resources including URLs and papers appearing in lecture videos. If you wish to dive more deeply into the topics covered this week, feel free to check out these optional references. You won’t have to read these to complete this week’s practice quizzes.
Papers
Konstantinos, Katsiapis, Karmarkar, A., Altay, A., Zaks, A., Polyzotis, N., … Li, Z. (2020). Towards ML Engineering: A brief history of TensorFlow Extended (TFX). http://arxiv.org/abs/2010.02013
Paleyes, A., Urma, R.-G., & Lawrence, N. D. (2020). Challenges in deploying machine learning: A survey of case studies. http://arxiv.org/abs/2011.09926
ML code fraction:
Sculley, D., Holt, G., Golovin, D., Davydov, E., & Phillips, T. (n.d.). Hidden technical debt in machine learning systems. Retrieved April 28, 2021, from Nips.cc https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf