Week 3 — Data
Data definition can be hard
- Data might suffer from inconsistent labelling which might mean the instructions for labellers are ambiguous.

Data Definition questions:
-
What is the input $x$?
Lighting? Contrast? Resolution?
What features need to be included?
-
What is the target label $y$?
How can we ensure labellers give consistent labels?
Unstructured v/s structured data
Unstructured data
- May or may not have huge collection of unlabeled examples $x$
- Humans can label more data.
- Data augmentation more likely to be helpful
Structured data
- May be more difficult to obtain more data
- Human labeling may not be possible (with some exceptions).
Small data vs Big Data
Small data
- Clean labels are critical
- Can manually look through dataset and fix labels
- Can get all the labelers to talk to each other
Big data
- Emphasis on data Process
Small data and label consistency
- Label consistency is very important for small data regime
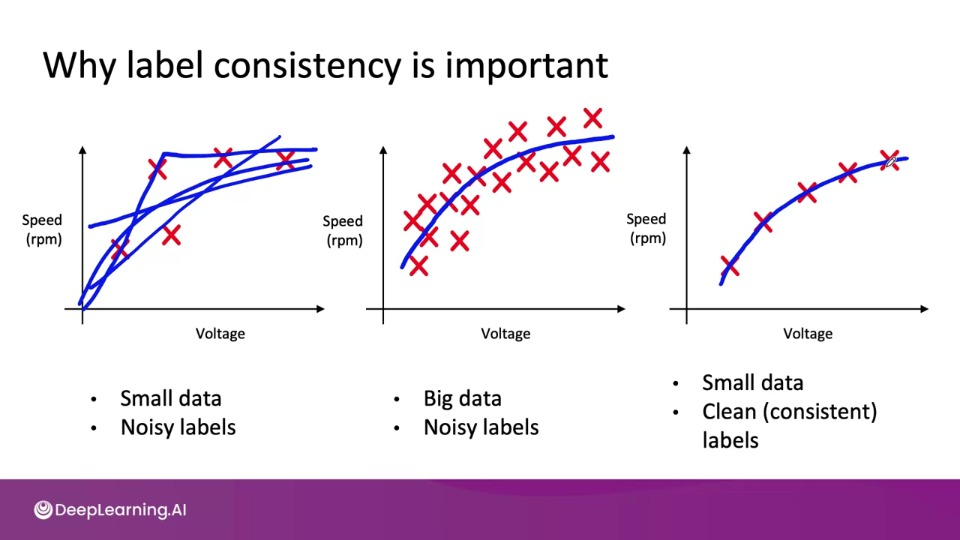
Big datasets can also have small data challenged for those long tail of rare events.
Improving label consistency
- Have multiple labelers label same example
- When there is disagreement, have MLE, subject matter expert (SME) and/or labelers discuss definition of $y$ to reach agreement.
- If labelers believe that $x$ doesn't contain enough information, consider changing $x$
- Iterate until it is hard to significantly increase agreement.
- Create a new class/label to capture uncertainty ("[unintelligible]" class for ambiguity in sound)
Small data v/s big data (unstructured data)
Small data
- Usually small numbers of labelers
- Can ask labelers to discuss specific labels
Big data
- Get to consistent definition with a small group
- Then send labeling instructions to labelers
- Can consider having multiple labelers label every example and using voting or consensus labels to increase accuracy.
Human Level Performance (HLP)
Why?
- HLP help estimate bayes error/ irreducible error to help with error analysis and prioritization.
- In academia, establish and beat a respectable benchmark to support publication.
- Business or product owner asks for 99% accuracy. HLP helps establish a more reasonable target.
- "Prove" the MLP system is superior to humans doing the job and thus the business or product owner should adopt it. (⚠️CAUTION)

Raising HLP
Often times the ground truth is just another human label. That means instead of trying of beat HLP, we should try to analyze why inspector didn't agree with the ground truth label.
- When the label $y$ comes from a human label, HLP << 100% may indicate ambiguous labelling instructions
- Improving label consistency will raise HLP.
- This makes it harder for ML to beat HLP. And that is good because the more consistent labels will raise ML performance, which is ultimately likely to benefit the actual application performance.
HLP is less frequently used for structured data problems where human labelers are less likely to involve but with few exceptions like, Based on network traffic, is computer hacked?, Spam account? Bot? like task.
Obtaining data
How long should you spend obtaining data?
- Get into this iteration loop as quickly as possible
-
Instead of asking: How long it would take to obtain $m$ examples?
Ask: How much data can we obtain in $k$ days?
-
Exception: If you have worked on the problem before and from experience you know you need $m$ examples.
You might also require to Brainstorm a list of data sources, cost and time it would take to get data. Other factors that might include: Data quality, privacy, regulatory constraints.
Labeling data
- Options: In-house vs. outsourced vs. crowdsourced
- Having MLEs label data is expensive. But doing this for just a few days is usually fine.
-
Who is qualified to label?
Specialized task like medical image diagnosis might require SME (subject matter expert) and can't be done anyone so easily.
And for some task like recommender systems, maybe impossible to label well.
-
Don't increase data by more than 10x at a time.
Data Pipeline
The important point is replicability.
POC( proof-of-concept):
- Goal is to decide if the application is workable and worth deploying.
- Focus on getting the prototype to work!
- It's ok if data pre-processing is manual. But take extensive notes/comment.
Production phase:
- After project utility is established, use more sophisticated tools to make sure the data pipeline is replicable.
- E.g., TensorFlow Transform, Apache Beam, Airflow,...
Meta-data, data provenance and lineage
Keep track of data provenance and lineage.
Data provenance: The documentation of where a piece of data comes from and the processes and methodology by which it was produced.
Data lineage: Data lineage includes the data origin, what happens to it and where it moves over time i.e., sequence of steps.
Metadata is data about data. Metadata can be really helpful to generate key insight during error analysis, spotting unexpected effects.
Balanced train/dev/test splits

Week 3 References
Week 3: Data Definition and Baseline
https://arxiv.org/pdf/1706.06969.pdf
Geirhos, R., Janssen, D. H. J., Schutt, H. H., Rauber, J., Bethge, M., & Wichmann, F. A. (n.d.). Comparing deep neural networks against humans: object recognition when the signal gets weaker∗. Retrieved May 7, 2021, from Arxiv.org website: