Week 2 — Key challenges in Modelling
- Doing well on training set (usually measured by average training error)
- Doing well on dev/test set(s).
- Doing well on business metrics/project goals
Maybe Low average error isn't good enough
Performance on disproportionately important examples might be more important.
- Less relevant "How to __" or informational and transactional queries might be forgiven by user whereas Navigational queries where the user wants to visit particular platform might not be forgiven by user.
- Model fairness is also an important aspect
- Think about recall vs precision
Skewed datasets with Rare classes can easily achieve low average error but in reality the model will be very naïve.
Establish a baseline
We can use Human Level Performance (HLP) as point of comparison or a naïve model as a baseline for improvement in next iteration. This gives a sense of what is irreducible error/Bayes error.
- Human Level Performance is often very useful for unstructured data as humans are very good at understanding unstructured data..
Ways to establish a baseline:
- Human level performance (HLP)
- Literature search for state-of-the-art (SOTA)/open source
- Quick-and-Dirty implementation
- Performance of older system
Tips for getting started
- Literature search to see what's possible (courses, blogs, open-source projects)
- Find open-source implementations if availaible
- A reasonable algorithm with good data will often outperform a great algorithm with not so good data.
Sanity-Check by trying to overfit a small training dataset before training on a larger set.
Error Analysis
Perform error analysis on the instances misclassified by trained model by iteratively finding tags related to the instances. Like for voice detection misclassified instances, find which has people's noise or low bandwidth.
Useful metrics for each tag:
- What fraction of errors has that tag?
- Of all data with that tag, what fraction is misclassified?
- What fraction of all the data has that tag?
- How much room for improvement is there on data with that tag?
Prioritizing what to work on

Only using "Gap to HLP" might not be good idea to work upon. Instead by measuring % of data with that tag and then estimating the decrease in error rate might give a better route for what to work upon.
Decide on most important categories to work on based on:
- How much room for improvement there is (like the above example)
- How frequently that category appears
- How easy is to improve accuracy in that category
- How important it is to improve in that category
What you can do to make improvement in that class?
- Collect more that data
- Use data augmentation to get more data
- Improve label accuracy/data quality
Skewed datasets
A skewed dataset is referred to dataset having a class imbalance problem. (few classes are outnumbered by other)
Instead of thinking just accuracy, use Confusion matrix and precision and recall.
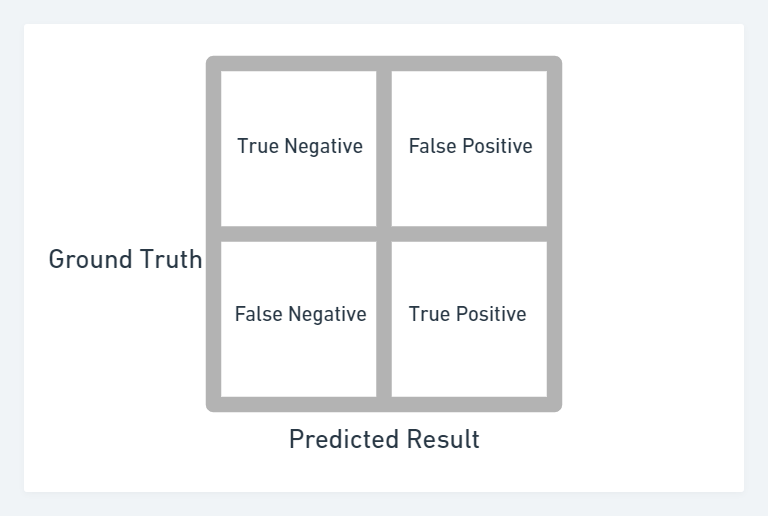
$$ \text{Recall} = \frac{TP}{TP+FN} $$
$$ \text{Precision} = \frac{TP}{TP+FP} $$
- Recall oriented tasks involve where consequences of False negatives are high like, Tumor detection.
- Precision oriented tasks involve where consequences of False Positive are high, like Search engine ranking, document classification.
If both are important then F1 scores can be helpful:
$$ F_1 = \frac{2.\text{Precision}.\text{Recall}}{\text{Precision + Recall}} $$
Performance auditing
Auditing Framework
Check for accuracy, fairness/bias, and other problems.
- Brainstorm the ways the system might go wrong
- Performance on subsets of data (e.g., ethnicity, gender)
- How common are certain errors (e.g., FP, FN)
- Performance on rare classes
- Establish metrics to assess performance against these issues on appropriate slices of data
- Get business/product owner buy-in

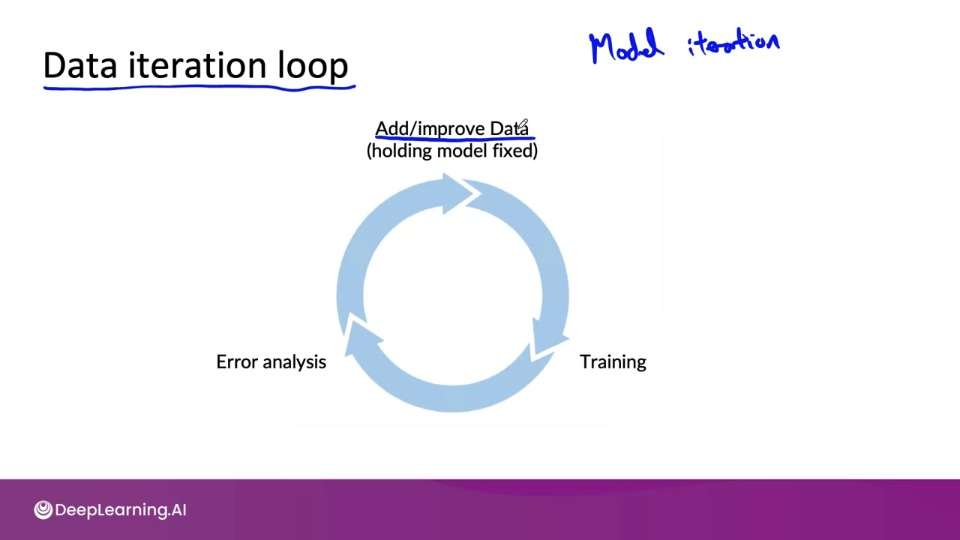
Data-centric vs Model-centric AI Development
Model-centric: Hold the data fixed and iteratively improve the code/model.
Data-centric: Hold the code fixed and iteratively improve the data,
Data-centric AI development using Data-augmentation
Data-augmentation can be really efficient way to generate more data as well as new maybe unseen variety of data especially for unstructured data.
Goal: Create realistic examples that
- The algorithm does poorly on, but
- humans (or other baseline) do well on
Checklist:
- Does it sound realistic?
- Is the $x \rightarrow y$ mapping clear? (e.g., can humans recognize speech?)
- Is the algorithm currently doing poorly on it?
Can adding data hurt performance?
For unstructured data problems, if:
- The model is large (low bias)
- The mapping $x \rightarrow y$ is clear (e.g., given only the input $x$, humans can make accurate predictions).
Then, adding data rarely hurts accuracy.

Adding Features if data-augmentation is not possible

Experiment Tracking
What to track?
- Algorithm/code versioning
- Dataset used
- Hyperparameters
- Results
Tracking tools:
- Text files
- Spreadsheet
-
Experiment tracking system
-
Information needed to replicate results
- Experiment results, ideally with summary metrics/analysis
- Perhaps also: Resource monitoring, visualization, mode error analysis
From Big data to Good Data
Try to ensure consistently high-quality data in all phases of the ML project lifecycle
Good data:
- Covers important cases (good coverage of inputs $x$)
- Is defined consistently (definition of labels $y$ is unambiguous)
- Has timely feedback from production data (distribution covers data data drift and concept drift)
- Is sized appropriately
Week 2 references
Week 2: Select and Train Model
If you wish to dive more deeply into the topics covered this week, feel free to check out these optional references. You won’t have to read these to complete this week’s practice quizzes.
Papers
Brundage, M., Avin, S., Wang, J., Belfield, H., Krueger, G., Hadfield, G., … Anderljung, M. (n.d.). Toward trustworthy AI development: Mechanisms for supporting verifiable claims∗. Retrieved May 7, 2021http://arxiv.org/abs/2004.07213v2
Nakkiran, P., Kaplun, G., Bansal, Y., Yang, T., Barak, B., & Sutskever, I. (2019). Deep double descent: Where bigger models and more data hurt. Retrieved from http://arxiv.org/abs/1912.02292