Week 1 — The ML project lifecycle
Ahhaha...You got your fine tuned model trained in Jupyter notebook...now what's next?
Get it delivered to customers...ASAP. right? maybe...
There are some hurdles before deploying the model in Production which needs to be taken care of like data drift, model updation, and deploying model to edge devices comes with it own set of challenges. It isn't all software engineering, it's more than that and that's what we are going are cover in this specialization on MLOps — Machine Learning Operations.
The whole specialization is divided into 4 courses:
-
Introduction to Machine Learning in Production
Taught by Andrew Ng
The overview of entire life cycle of Machine learning Project — from scoping and getting data to modeling and deployment.
-
Machine Learning Data Lifecycle in Production
Taught by Robert Crowe
This will be about the Data Pipelines.
-
Machine Learning Modeling Pipelines in Production
After data gathering comes modeling, we will learn managing modeling resources to best serve inference requests and minimize cost of training and also apply to analytics to better understand model.
-
Deploying Machine Learning Models in Production
At last comes the production, where we are ready to serve customers. This will be about how to built deployment pipelines and variety of infrastructure to better serve the needs and keep the production environment up in top condition.
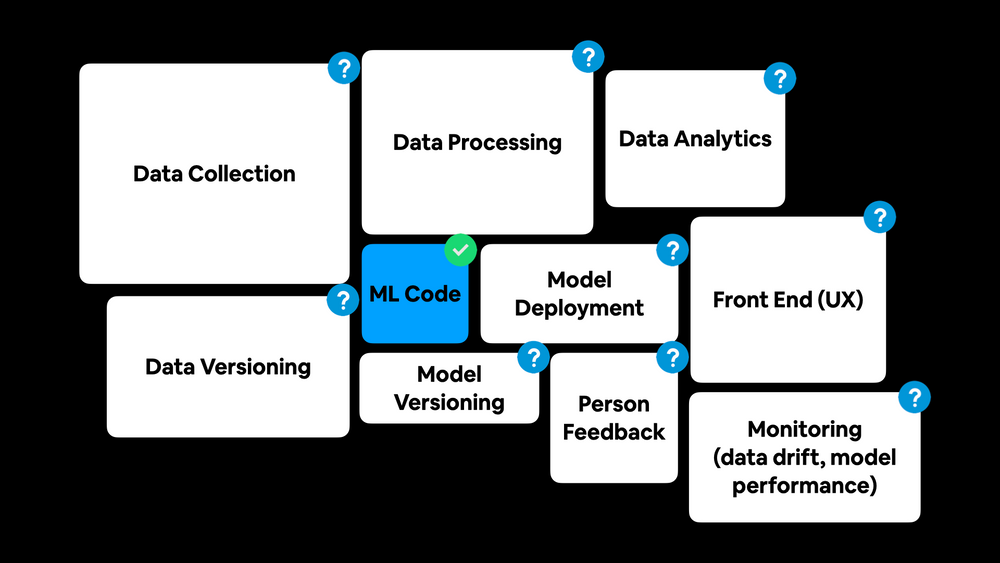 Image by Daniel Bourke | Source
Image by Daniel Bourke | Source
ML code is just a very small component in a machine learning project. The other non-ML code makes up for what is said to be a useful product.
The ML Project Lifecycle
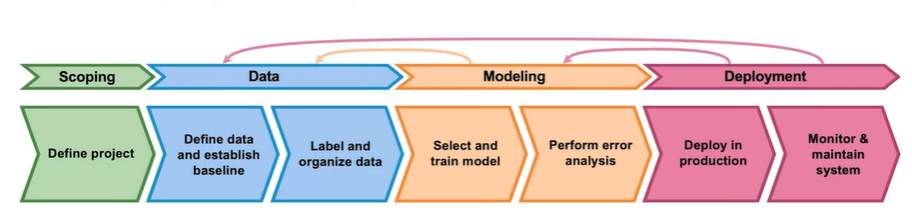 Image by Steven Layett and Daniel Pipryata from landing.ai
Image by Steven Layett and Daniel Pipryata from landing.ai
The first stage is Scoping:
- Decide the scope of the project, who is going to use it by thinking from user's perspective
- Decide on key metrics
- Estimate resources and timeline
The second stage is to do with Data
Ask questions like:
- Is the data labeled consistently?
- Is the data balanced?
The third stage is Modeling which is an iterative process which often leads us to question data and learn what might be wrong with data.
The fourth and final stage is Deployment, either in cloud accessible via APIs or directly on edge devices. This also involves monitoring and maintaining the system to check for visible signs of degrading performance or shift in distribution of data (data drift).
MLOps or Machine Learning Operations is an emerging discipline, and comprises a set of tools and principles to support progress through the ML project lifecycle. It involves four stages Scoping, Data gathering and analysing, Modeling and Deployment.
Deployment Key Challenges
The issues can be broadly categorised into 2:
Machine Learning/statistical issues
-
Concept Drift: The mapping from $x\rightarrow y$ changes
Concept drift is a phenomenon where the statistical properties of the target variable ($y$ - which the model is trying to predict), change over time.
e.g., Say you are building the house price prediction system then concept drift will be said to occur when the size of the house remains same but price increases.
-
Data Drift: The distribution of the data ($x$) changes
For same example data drift may occur when people start building larger/smaller houses.
Software engineering issues
- Realtime or Batch
- Cloud or Edge
- Compute resources (CPU/GPU/memory)
- Latency, throughput (QPS) (Queries Per Second)
- Logging
- Security and privacy
Deployment patterns
Common deployment cases:
- New product/capability
- Automate/assist with manual task
- Replace previous ML system
Key ideas:
- Rolling release/upgrade
- Rollback
Shadow mode deployment is where the ML system shadows the human and runs in parallel but not used actively for making any kind of decisions. The only purpose of such kind of deployment is to gather more data and insight before full deployemnt
Canary deployment is gradual deployment where the system is only allowed to handle small fraction of traffic while monitoring and gradually ramping up traffic.
Blue green deployment is a method of installing changes to service by swapping alternating production (older service) and staging server (newer service). This swapping can be either complete or partial.
Degrees of Automation
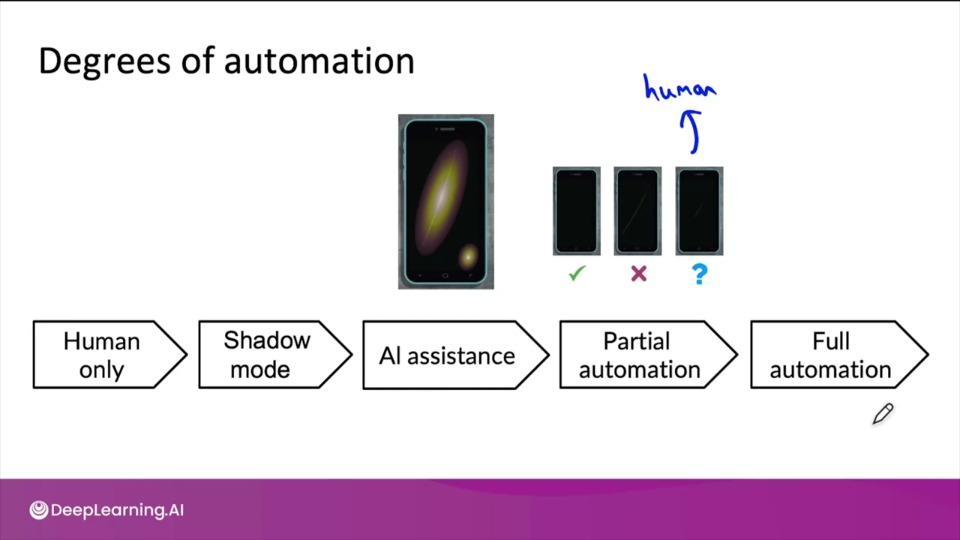 Image by DeepLearning.AI
Image by DeepLearning.AI
Monitoring
- Brainstorm things that could go wrong
- Brainstorm a few statistics/metrics that will detect the problem
- It's ok to use many metrics initially and gradually remove the ones you find not useful
Software metrics - Memory, compute, latency, throughput, server load
Input metrics - Average input length, average input volume, number of missing values etc
Output metrics - Times return " " (null), times user redoes search, times user switches to typing
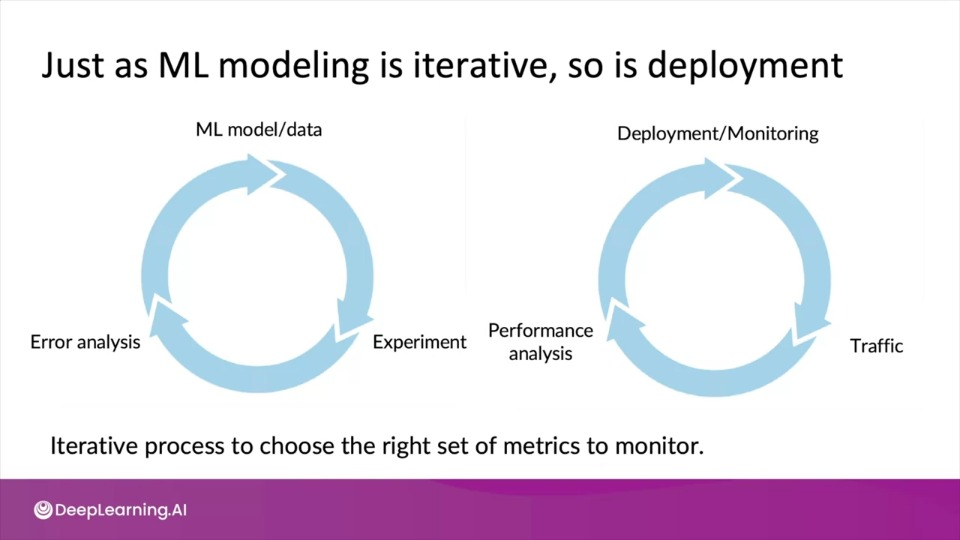
By monitoring different metrics we can set thresholds for alarms/notification.
This also can prompts to update/retrain our models either manually or automatically.
Pipeline Monitoring
There can also be components to our system that are used before the data even gets as input. We might need to monitor those components as well.
We may also ask, How quickly do the data change?
- User data generally has slower drift
- Enterprise data (B2B applications) can shift faster
Week 1 references
Week 1: Overview of the ML Lifecycle and Deployment
If you wish to dive more deeply into the topics covered this week, feel free to check out these optional references. You won’t have to read these to complete this week’s practice quizzes.
A Chat with Andrew on MLOps: From Model-centric to Data-centric
Papers
Konstantinos, Katsiapis, Karmarkar, A., Altay, A., Zaks, A., Polyzotis, N., … Li, Z. (2020). Towards ML Engineering: A brief history of TensorFlow Extended (TFX). http://arxiv.org/abs/2010.02013
Paleyes, A., Urma, R.-G., & Lawrence, N. D. (2020). Challenges in deploying machine learning: A survey of case studies. http://arxiv.org/abs/2011.09926
Sculley, D., Holt, G., Golovin, D., Davydov, E., & Phillips, T. (n.d.). Hidden technical debt in machine learning systems. Retrieved April 28, 2021, from Nips.c https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf