Week 2 — Model Serving Architecture, Scaling Infrastructure and More.
Model Serving Architecture
On Prem
- Train and deploy on your own hardware infrastructure
- Manually procure hardware GPUs, CPUs etc
- Profitable for large companies running ML projects for longer times
- Can use open source, pre-built servers
- TF-Serving, KF-Serving, NVidia and more
On cloud
- Train and deploy on cloud choosing from several service providers
- Amazon Web Services, Google Cloud Platform, Microsoft Azure
- Create VMs and use open source pre-built servers
- Use the provided ML workflow
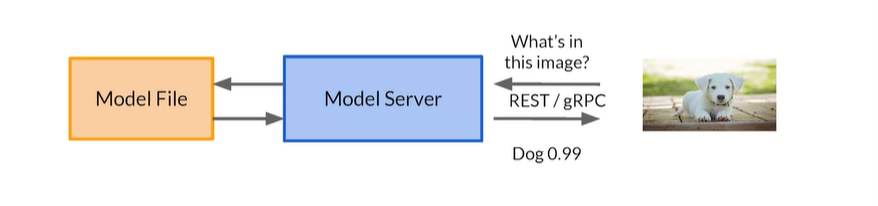
Model Servers
- Simplify the task of deploying machine learning models at scale
- Can handle scaling, performance, some model lifecycle management etc.,
Model Servers: TensorFlow Serving
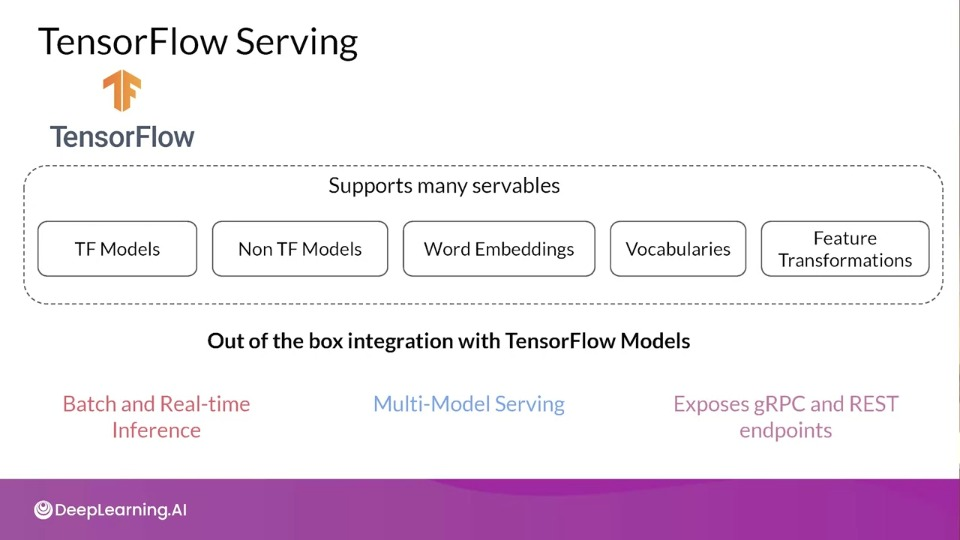
TensorFlow Serving allows:
- Batch and Real-Time Inference: batch inference if you have such requirement like in the case of recommendation engine, or real-time for end user facing application
- Multi-Model serving: allows multiple models for the same task and the server chooses between them, this can be useful for A/B testing, audience segmentation or more.
- Exposes gRPC (Remote Procedure Call) and REST endpoints
TensorFlow Serving Architecture
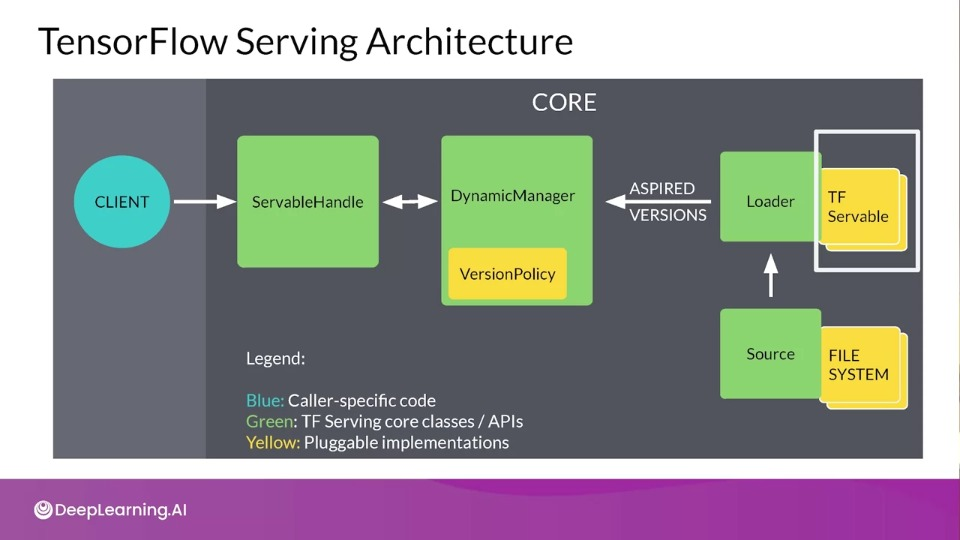
A typical servable is a TensorFlow saved model but it could also be something like a lookup up table for an embedding.
The Loader manages a servable's lifecycle by standardizing the API for loading and unloading a servable. The loader API enables common infrastructure independent form specific learning algorithms, data or whatever product use cases were involved.
A Source creates a loader and notifies DynamicManger of the aspired version.
Together this will create Aspired versions representing the set of servable versions that should be loaded and ready.
The DynamicManager handles the full life cycle of the servable, including loading the servables, serving the servables and unloading the servables. The manager will listen to the Sources and will track all of the versions according to a VersionPolicy.
When the Client request a handle to new version, DynamicManager returns a handle to the new version of the servable.
The ServableHandle provides the exterior interface to the client
Model Servers: Other Providers
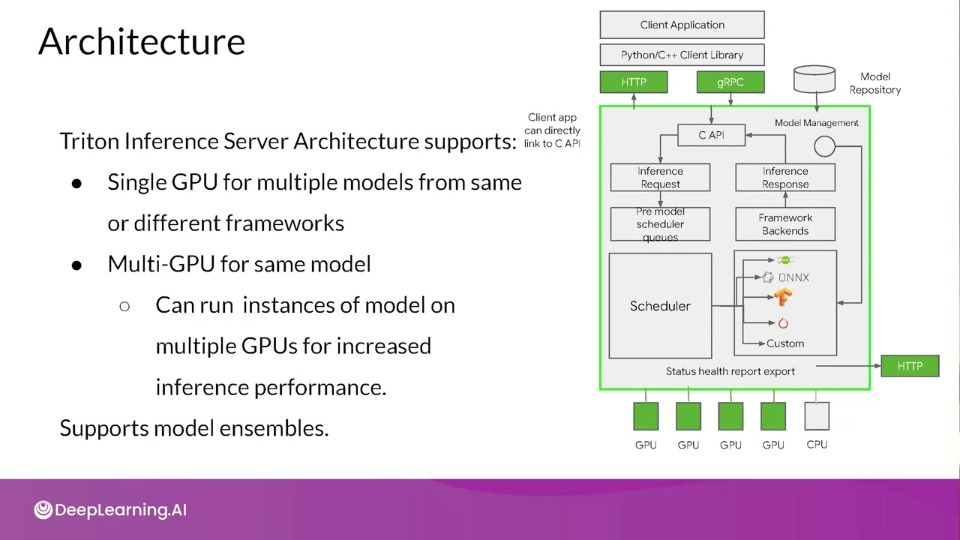
NVIDIA Triton Inference Server
- Simplifies deployment of AI models at scale in production
- Open source inference serving software
- Deploy trained models from any framework
- TensorFlow, TensorRT, PyTorch, ONNX Runtime or a custom framework
- Models can be stored on:
- Local storage, AWS S3, GCP, Any CPU-GPU architecture (cloud, data centre or edge)
- HTTP REST or gRPC endpoints are supported
Torch Serve
- Model serving framework for PyTorch models
- Initiative from AWS and Facebook
- Supports Batch and Real-Time Inference
- Supports REST Endpoints
- Default handlers for Image Classification, Object Detection, Image Segmentation, Text Classification.
- Supports Multi-Model Serving
- Monitor Detail logs and Customized Metrics
- A/B Testing
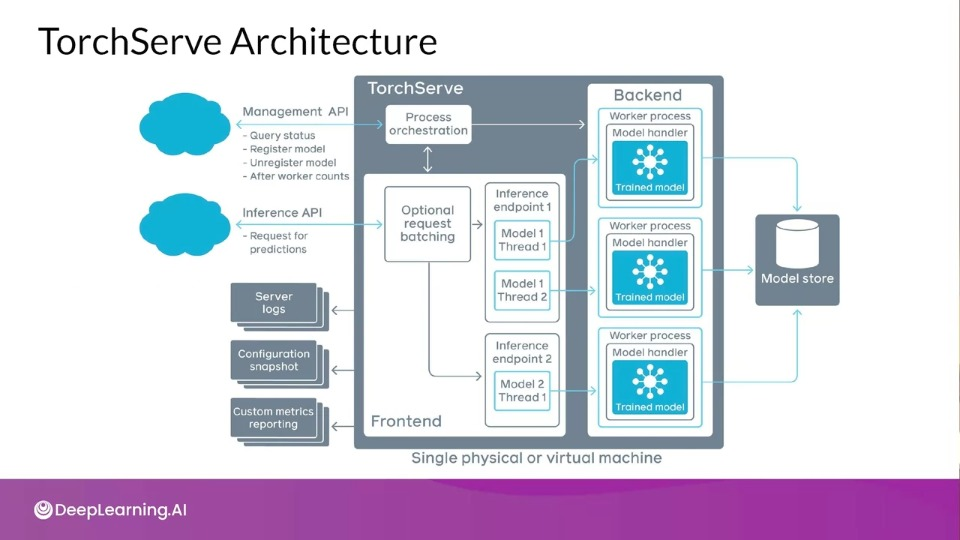
The Frontend is responsible for handling both requests and responses.
The Backend uses model workers that are running instances of the model loaded form a model store, responsible for performing the actual inference.
KFServing

Documentation on model servers
Documentation on model servers
The video lecture covered some of the most popular model servers: TensorFlow Serving, TorchServer, KubeFlow Serving and the NVidia Triton inference server. Here are the links to relevant documentation for each of these options:
Scaling Infrastructure
Why is Scaling Importatnt?
- Large NN training might take too long on single CPU or GPU, so distributed training and scaling is required.
- Larger the network more parameters and hyperparameters need to be tuned and fine-tuned.
- In production settings, huge volume of request to single server instance may overwhelm it.
Two main ways to scale:
-
Horizontal Scale
Adding more powerful hardware to the serving infrastructure, more RAM, more storage, faster CPU & GPU.
-
Vertical Scale
Adding more components to the infrastructure.
More CPUs, GPUs or instantiating more servers.
Why Horizontal Over Vertical Scaling?
- Benefit of elasticity: Shrink or grow no of nodes based on load throughput, latency requirements.
- Application never goes offline: No need for taking existing servers offline for scaling
- No limit on hardware capacity: Add more nodes any time at increased cost
Keep an eye out for three thing:
- Can I manually scale?
-
Can I autoscale?
How much latency?
-
How aggressive the system at spinning up and down based on my need?
How can I manage my additional VMs to ensure that they have the content on them that I want?
Containerization
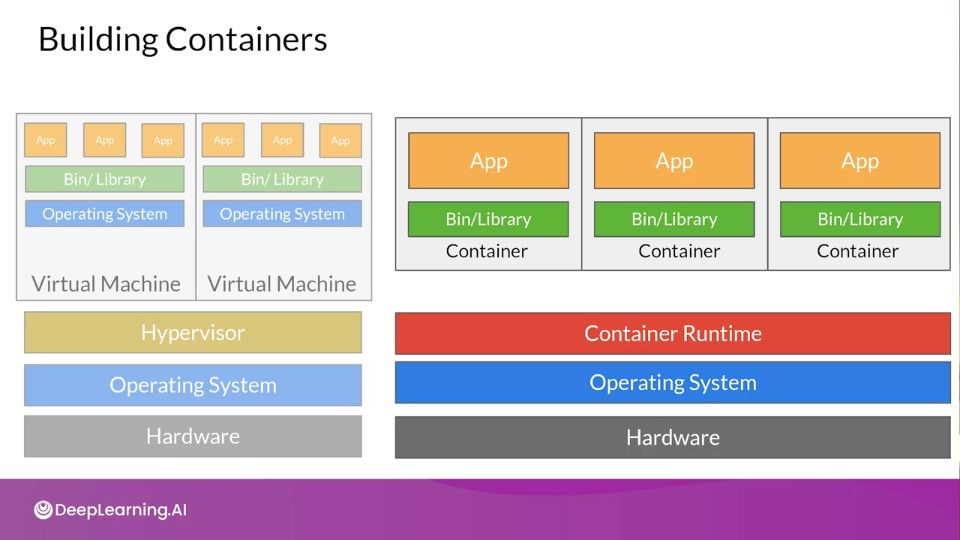
Advantages:
- Less OS requirements - more apps.
- Abstraction
- Easy deployment based on container runtime
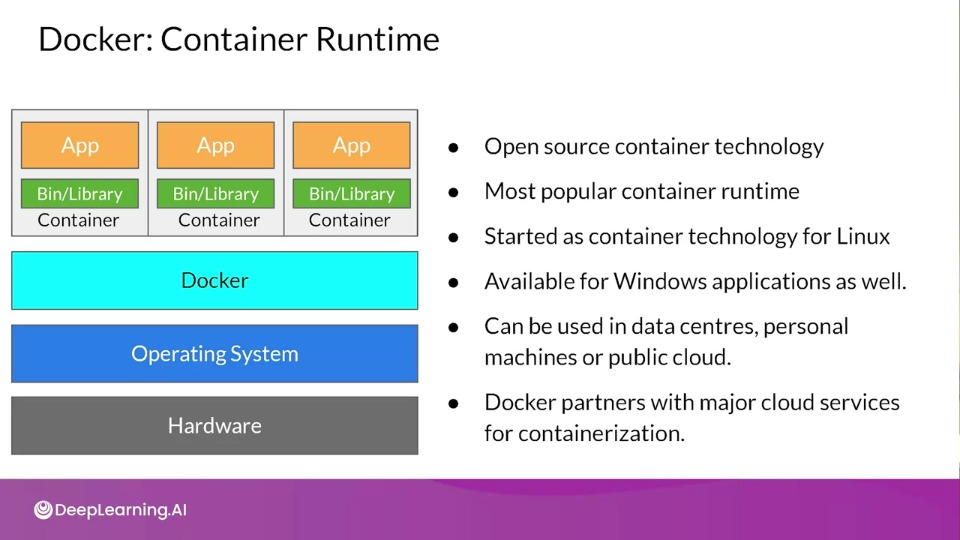
Docker
Container Orchestration
The idea behind container orchestration is to have a set of tools like managing the lifecycle of containers, including their scaling.
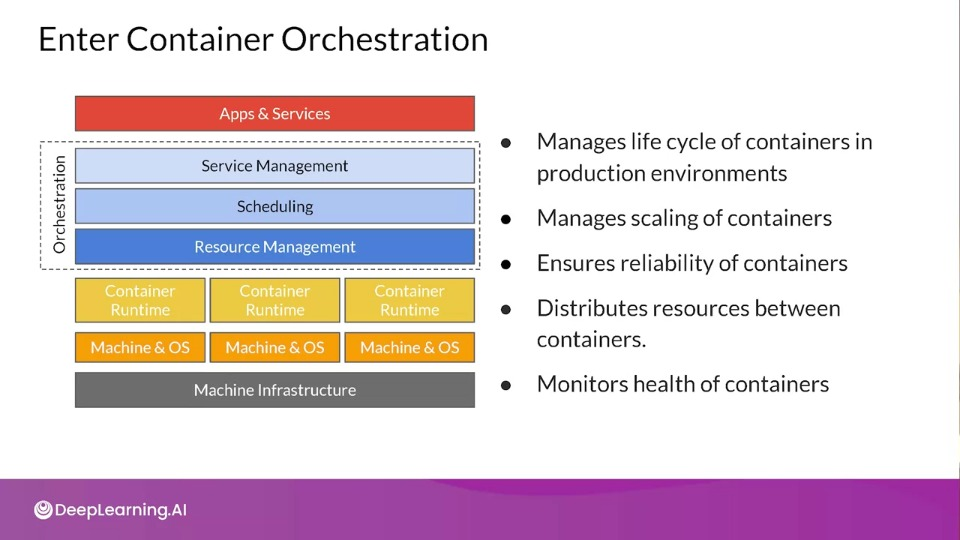
Popular container Orchestration Tools include:
- Kubernetes
- Docker Swarm
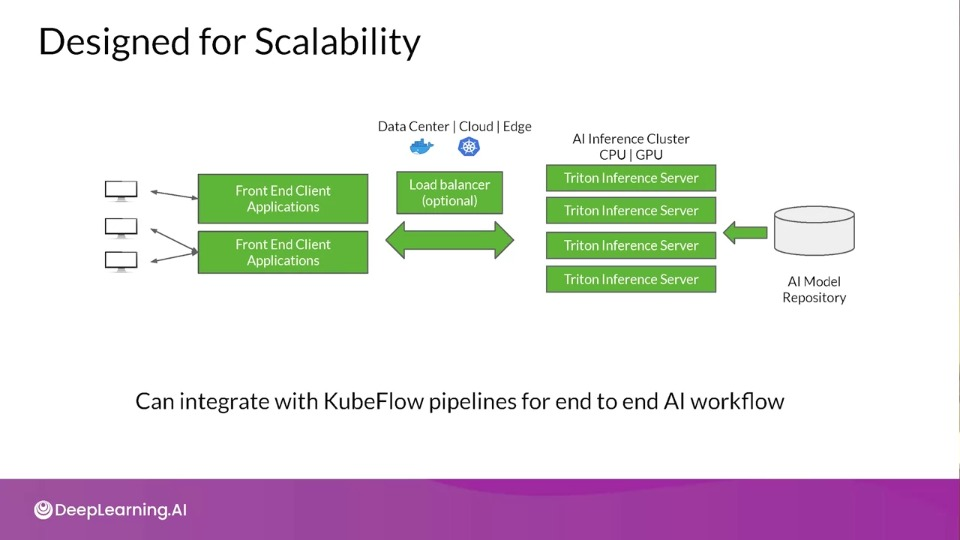
ML Workflows on Kubernetes - KubeFlow
- Dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable
- Anywhere you are running Kubernetes, you should be able to run Kubeflow
- Can be run on premise or on Kubernetes engine on cloud offerings AWS, GCP, Azure etc.,
Learn about scaling with boy bands
Learn about scaling with boy bands
In the next few minutes you’ll learn about horizontal and vertical scaling. Before going into that, here’s a fun case study on managing scale.
In this extreme case a famous boy band called ‘One Direction’ hosted a 10-hour live stream on YouTube, where they instructed fans to go visit a web site with a quiz on it every 10 minutes. This led to a really interesting pattern in scalability where the application would have zero usage for the vast majority of the time, but then, every 10 minutes may have hundreds of thousands of people hitting it.
It’s a complex problem to solve when it comes to scaling. It could be very expensive to operate. Using smart scaling strategies, Sony Music and Google solved this problem very inexpensively. Laurence isn’t allowed to share how much it cost for the cloud services, but, when he and several of the other engineers went out for celebration drinks after the success of the project, the bar bill was more expensive than the cloud bill. (And they didn’t drink a lot!)
Check out the talk about how scaling worked for this system here: https://www.youtube.com/watch?v=aIxNm5Eed_8
Learn about the event and the app here: https://www.computerweekly.com/news/2240228060/Sony-Music-Google-cloud-One-Directions-1D-Day-event-platform-services
Exploring Kubernetes with KubeFlow
Explore Kubernetes and KubeFlow
In the videos we explored Kubernetes and KubeFlow, and before going further, I strongly recommend that you have a play with them to see how they work.
Kubernetes
First is Kubernetes. The site is https://kubernetes.io/, and at the top of the page, there’s a big friendly button that says ‘Learn Kubernetes Basics’:
Click on this, and you’ll be taken to: https://kubernetes.io/docs/tutorials/kubernetes-basics/
From here you can go through a lesson to create a cluster, deploy and app, scale it, update it and more. It’s interactive, fun, and worth a couple of hours of your time to really get into how Kubernetes works.
You may also want to check this video tutorial out.
KubeFlow
For KubeFlow, visit: https://www.kubeflow.org/, and at the top of the page, there’s a Get Started button.
Click on it to go to the tutorials. It doesn’t have the nice interactive tutorials that Kubernetes has, but, if you can, try to at least install KubeFlow on one of the deployment options listed on this page – even if it’s just your development machine. If you find it tricky to follow, don't worry because you will have an ungraded lab next week that will walk you through installing Kubeflow Pipelines (one of the Kubeflow components) in Kubernetes. In the meantime, you can watch this playlist particularly video #5 on Kubeflow Pipelines to get a short intro to this toolkit.
Onine Inference
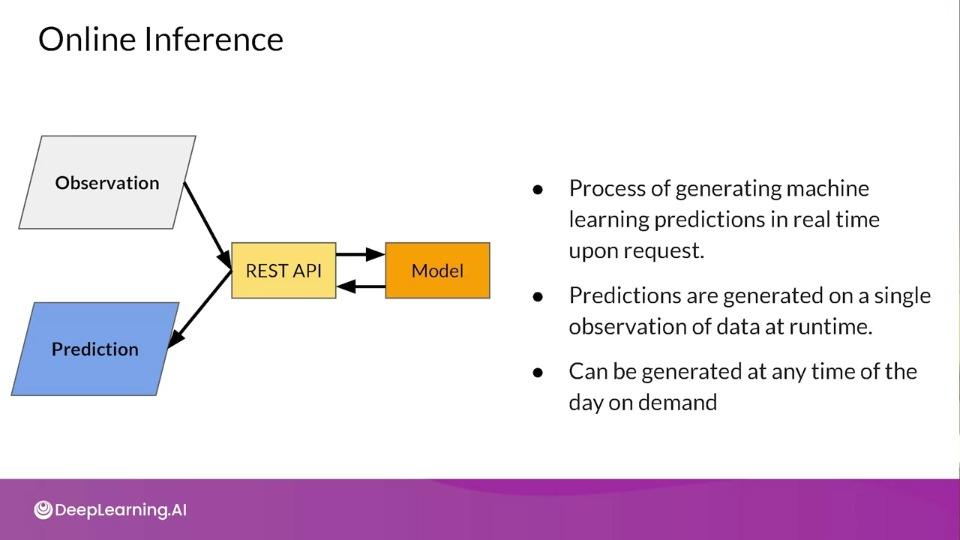
Optimising ML Inference
-
Latency
Latency is the total delay as experienced by the user. The model might be working fine having least possible latency, but the problem may be arise with the UI, or carrier of data. So latency need to seen as a whole metric for the system.
-
Throughput
The throughput measured in request managed per unit time is often more important for non-customer facing systems. While it might still be very important metric in case of user facing system.
-
Cost
Both latency and throughput along with many other has to taken into account to be balanced out with limited cost.
Inference Optimization — Where to optimize?
Infrastructure
Scale with additional or more powerful hardware as well as containerized virtualized environments.
Model Architecture
Understand the model architecture and metrics that goes behind to training and testing.
Often there's a trade off between inference speed and accuracy.
Model Compilation
If we know the hardware on which we're going to deploy the model, for example, a particular type of GPU there's often a post training step that consists of creating a model artifact and a model execution runtime that's finally adapted to the underlying support hardware.
We can refine model graph and inference runtime to reduce memory consumption and latency
Additional Optimizations
Additional optimizations can be done for infrastructure like introducing a cache, for faster lookup for relevant information

Data Preprocessing
Often the data given to the system is not actually in the format the model supports, the data need to be pre-processed. Question is where this preprocessing is supposed to be done?
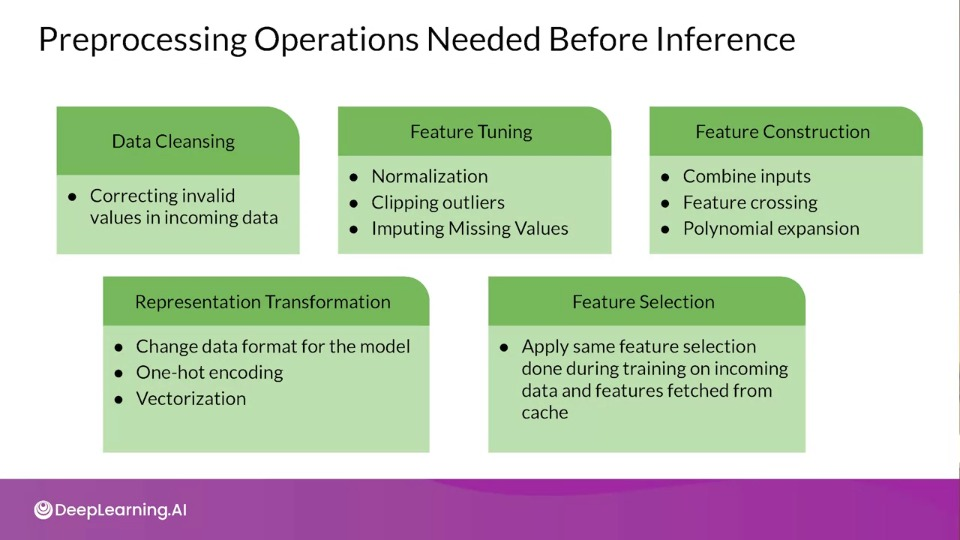
And post-processing
Offcourse model isn't going to output that might be interpretable by a human, and some kind of post processing might needs to done in order to completed the whole process.
Data Pre-processing
Data preprocessing
Apache Beam is a product that gives you a unified programming model that lets you implement batch and streaming data processing jobs on any execution engine. It’s ideally suited for data preprocessing!
Go to https://beam.apache.org/get-started/try-apache-beam/ to try Apache Beam in a Colab so you can get a handle on how the APIs work. Make sure you try it in Python as well as Java by using the tabs at the top.
Note: You can click the Run in Colab button below the code snippet to launch Colab. In the Colab menu bar, click Runtime > Change Runtime type then select Python 3 before running the code cells. You can get more explanations on the WordCount example here and you can use the Beam Programming Guide as well to look up any of the concepts.
You can learn about TensorFlow Transform here: https://www.tensorflow.org/tfx/transform/get_started . It also uses Beam style pipelines but has modules optimized for preprocessing Tensorflow datasets.
Batch Inference Scenarios
Prediction based on batch inference is when your ML model is used in a batch scoring job
for a large number of data points, where predictions are not required or not feasible to generate in real-time
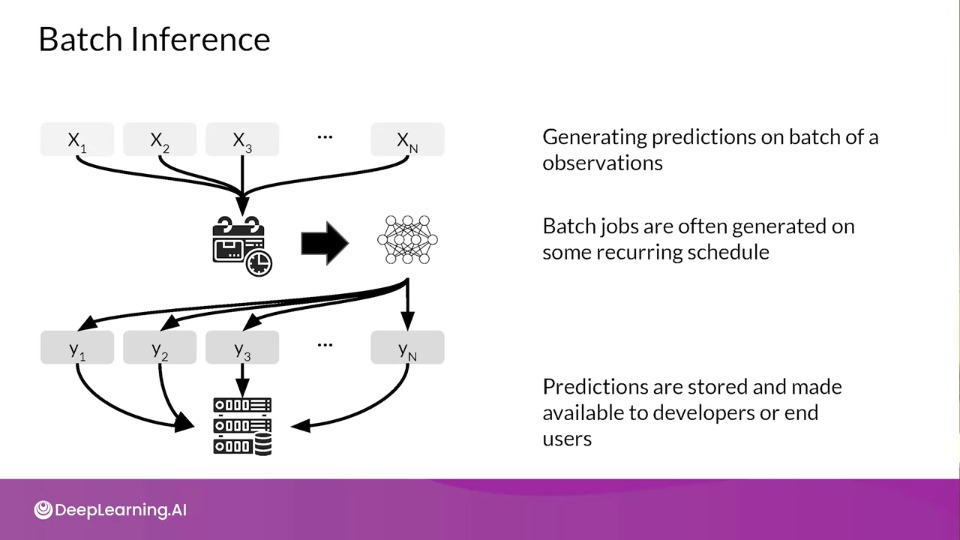
These batch jobs for prediction are usually on some recurring schedule like daily, weekly or monthly. Predictions are then stored in a database which can be made available to developers or end-users.
Advantages of Batch Inference
- Complex machine learning models for improved accuracy
- Caching not required
- This leads to lower cost
- Long data retrieval does not become a problem
Disadvantages of Batch Inference
- Long Update latency
- Predictions based on older data. Possible solutions:
- In that case recommendations can come from same age bracket
- Or recommendations can come from same geolocation
Important Metrics to Optimize
Most important metric to optimize while performing batch predictions: Throughput
- Prediction service should be able to handle large volumes of inference at a time.
- Predictions need not be available immediately
- Latency can be compromised
How to Increase Throughput?
- Use hardware accelerators like GPU's, TPU's.
- Increase number of servers/workers
- Load several instances of model on multiple workers to increase throughput



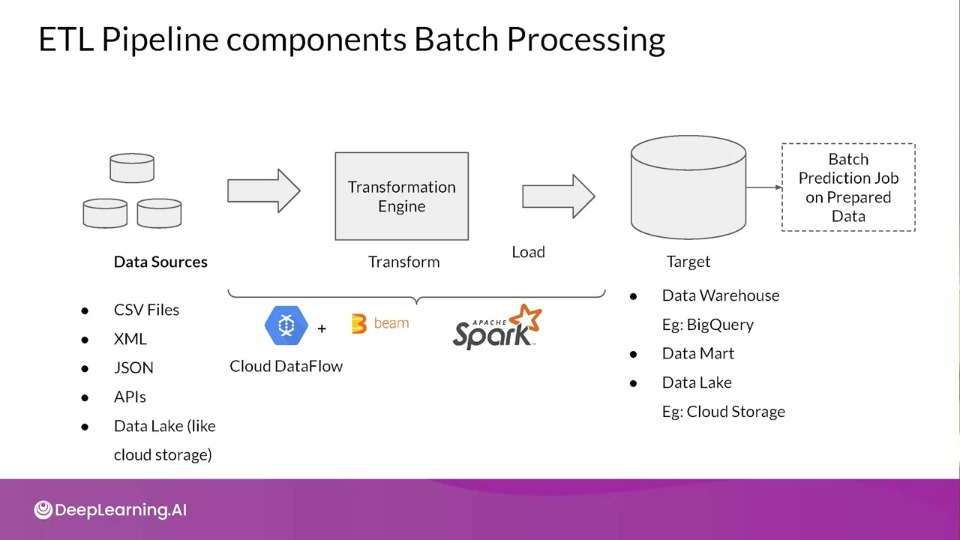
Batch Processing with ETL
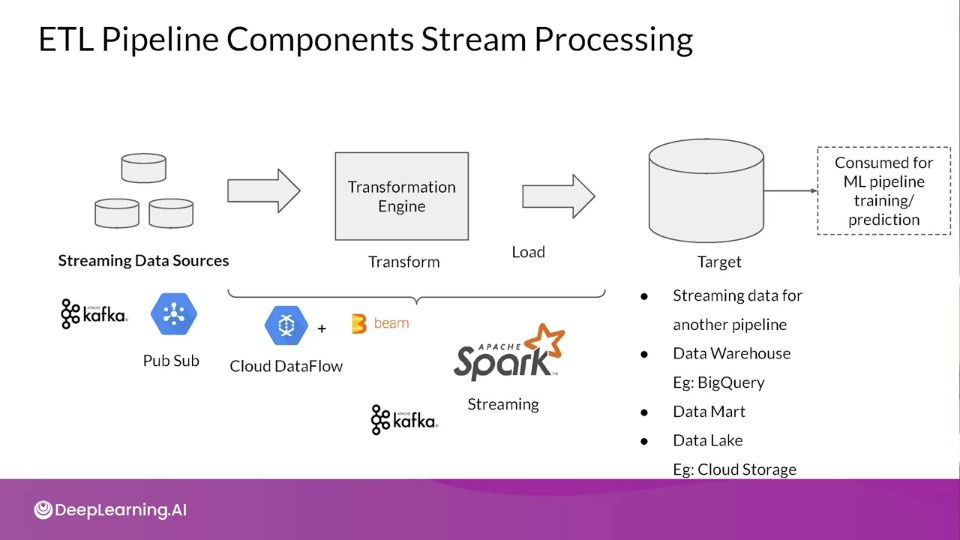
Data Processing — Batch and Streaming
- Data can be of different types based on the source
- Batch Data
- Data processing can be done on data available in huge volumes in data lakes, from csv files, log files, etc.,
- Streaming Data
- Real-time streaming data, like data from sensors
ETL on Data (Extract, Transform and Load)
Before data is used for making batch predictions:
- It has to be extracted from multiple sources like log files, streaming sources, APIs, apps, etc.,
- Transformed
- Loaded into a database for prediction
This is done using ETL Pipelines
ETL Pipelines
Set of processes for
- extracting data from data sources
- Transforming data
- Loading into an output destination like data warehourse
From there data can be consumed for training or making predictions using ML models.
Distributed Processing
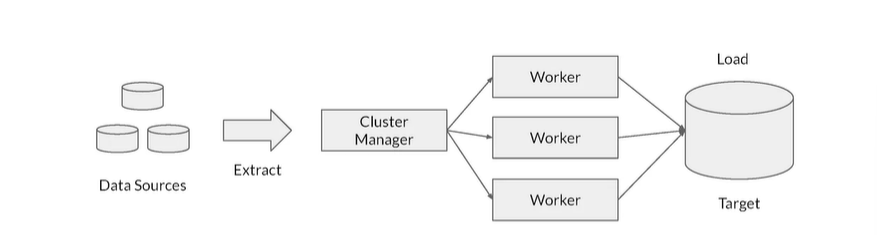
- ETL can be performed on huge volumes of data in distributed manner
- Data is split into chunks and parallely processed by multiple workers
- The results of the ETL workflow are stored in a database
- Results in lower latency and higher throughput of data processing